Intro to Load Balancers

Lately, I've been on a quest, searching for resources that could break down the concept of Load Balancers in a way that's digestible yet not superficial.
I aimed to discover something neither too generalistic nor too focused on implementation details or specific technologies. My goal was to grasp the role of load balancers within the high-level system architecture. Turns out, it's more challenging than I anticipated.
Along the way, I stumbled upon a great blog post by Matt Klein and explored some insightful big-tech engineering blogs. Despite these great resources, I still had more questions than answers.
While I do not have expertise or practical experience in this subject, I'm eager to learn alongside you.
I prefer avoiding acronyms, however, we'll use a few for brevity, LB for the load balancer, SSL for the secure sockets layer, etc. Despite aiming for consistent terminology, the vast information might lead to occasional inconsistencies, such as different terms for similar concepts like backends, machines, servers, and nodes.
The Problem
Let's play a game taken from the Google SRE book.
Imagine this: You're at the heart of a buzzing startup, surrounded by great minds.
Together, you are building a web service and fortunately enough humans already managed to create a supercomputer with unlimited CPU, RAM, and all the resources you could imagine.
Here is the question, would one supercomputer serve all your needs?
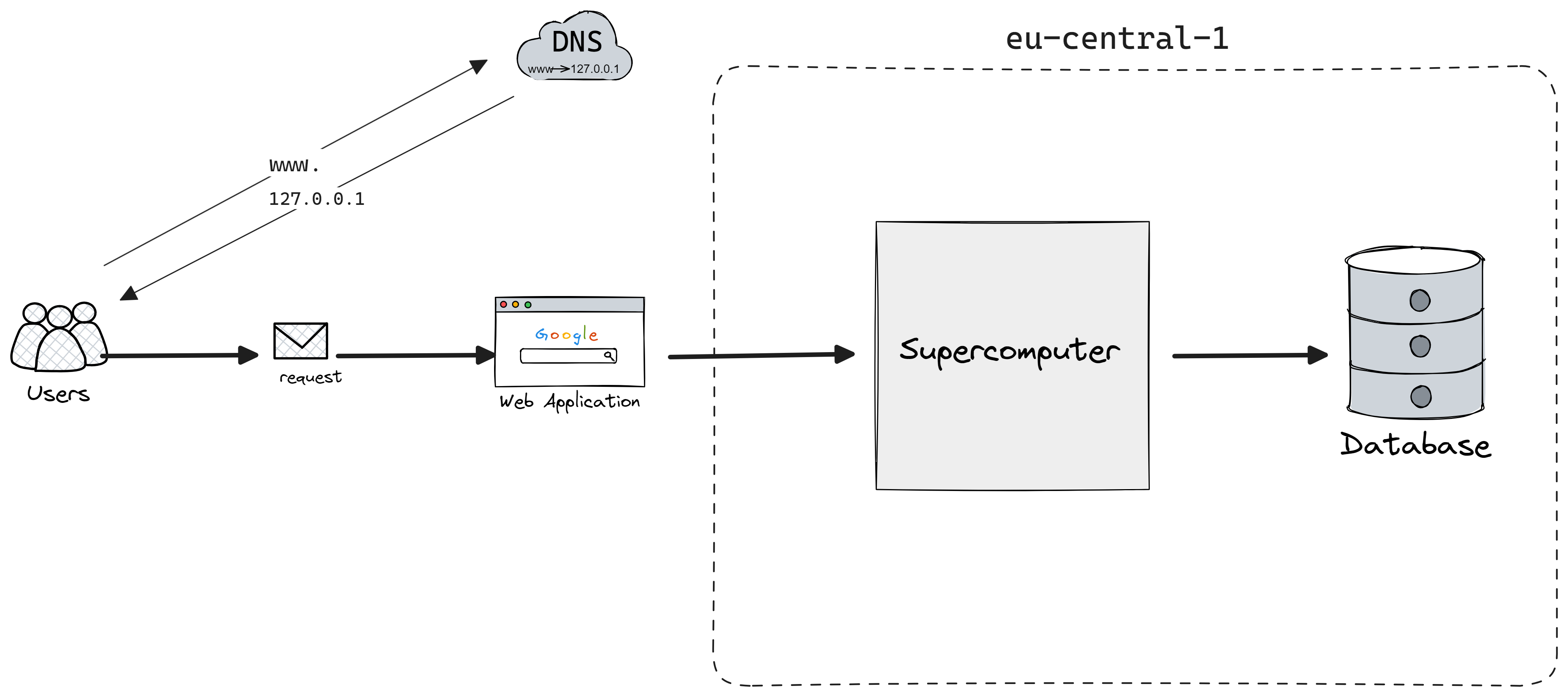
As you probably know this solution is far from perfect, and there are a few reasons for that:
Your server is a single point of failure. Whether you will have a monolith or move to microservices, you want to have at least two instances.
Latency: if you have users all around the globe, you can not have the same latency for every user while having a single server.
Scalability constraints: If data volume, read load, or write load grows bigger than a single server can handle, you can spread the load across different machines. Speed of light is still a limitation factor on how quickly we can send data over the network.
Cost-efficiency: the cost for more powerful machines grows faster than linearly. After some point, it is much cheaper to buy many average machines than one powerful one.
The Solution
So, you decide to add another server to share the load. Great! But now, you're faced with a new puzzle: How do you decide which server handles which request? How to do it optimally?
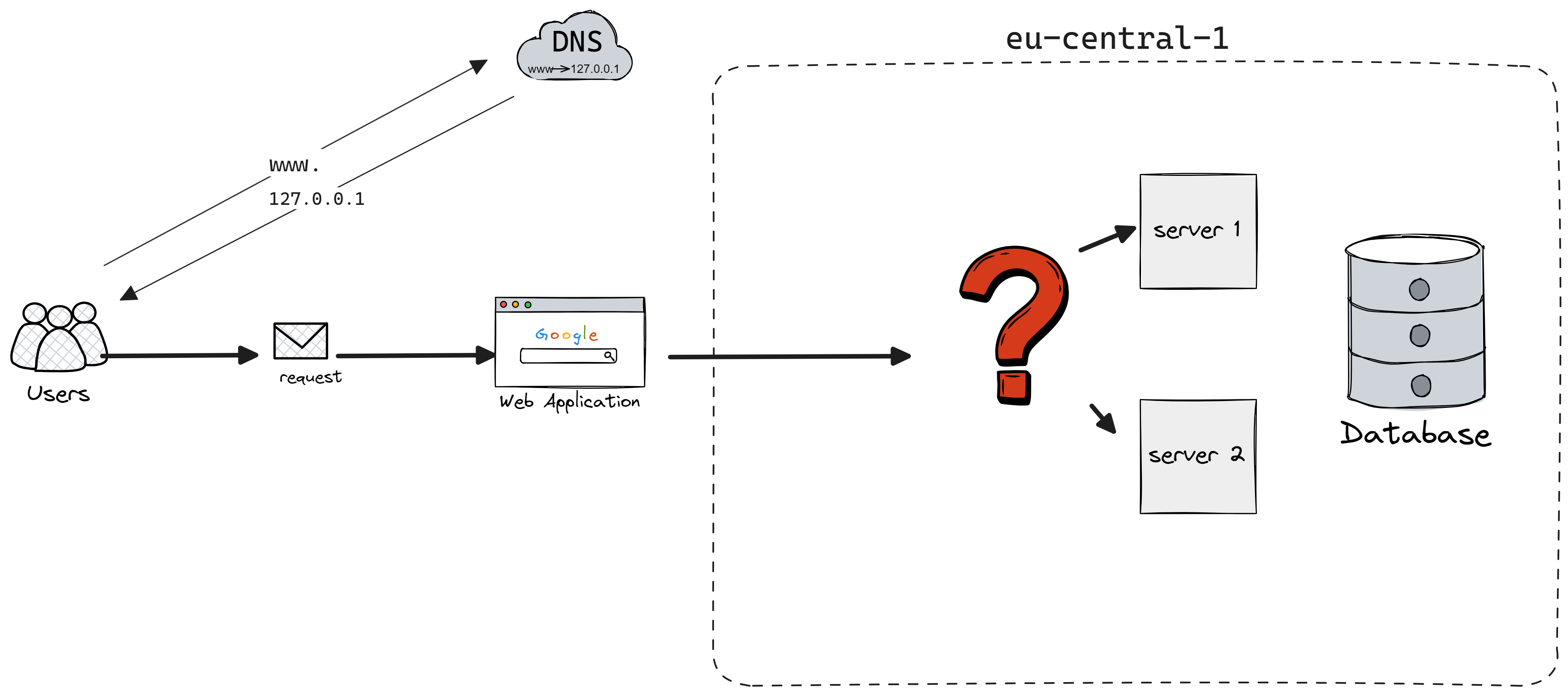
You've likely noticed we're overlooking a key element, and you're right: Load Balancer is the solution here.
What is a Load Balancer
The primary goal of using Load Balancer is not to overburden with huge incoming traffic which may lead to server crashes or high latency. Load Balancer routes the traffic to each server based on some sort of routing policies (algorithms).
Here are just some of the most used features of load balancers:
Load distribution
Stable client endpoints (IPs) over always-changing servers
SSL termination, Authentication, throttling, firewall
DoS, DDoS protection
Caching
A/B testing
HTTP compression, content filtering (by modifying traffic on the fly)
Types of Load Balancers
Based on Configuration
Hardware Load Balancers are also known as L4-L7 routers which are capable of handling all kinds of HTTP(S), TCP, UDP, and other protocols. When using specialized hardware, the load distribution is generally faster, leading to better performance. They are expensive to buy and configure, which is the reason a lot of service providers use them only as the first entry point for user requests (discussed later). Also, it can limit your scalability as expanding beyond initial hardware capacity can be challenging. From hardware Load Balancers traffic is distributed to Internal Software Load Balancers.
Software Load Balancers are applications that run on general-purpose servers (ec2, containers, etc). Historically, routers and load balancers have been provided as extremely expensive proprietary hardware. Nowadays there are many OSS solutions as well as cheaper options. What was before the domain of vendors like F5 is now possible with L7 sophisticated load balancers: NGINX, HAProxy, and Envoy. The limitation of Software LB is it can’t compete with Hardware LB on performance and also when used on shared infrastructure, there can be competition for resources, leading to potential performance degradation.
Virtual Load Balancers are deployed in virtualized or cloud environments, where they can be easily provisioned, configured, and managed through software interfaces. Examples are Amazon Elastic Load Balancing (ELB), NGINX (on-cloud), Azure Load Balancer, F5 BIG-IP Virtual Edition, etc.
Based on Functions
Before we jump into more details, let’s do a quick review of the TCP/IP network layer.
When a client tries to access a server, every request passes through all seven layers (except routers which are based on L3, and cases when demultiplexing happens before). A Load Balancer that works on a specific layer can perform different operations based on the metadata of the same connection.
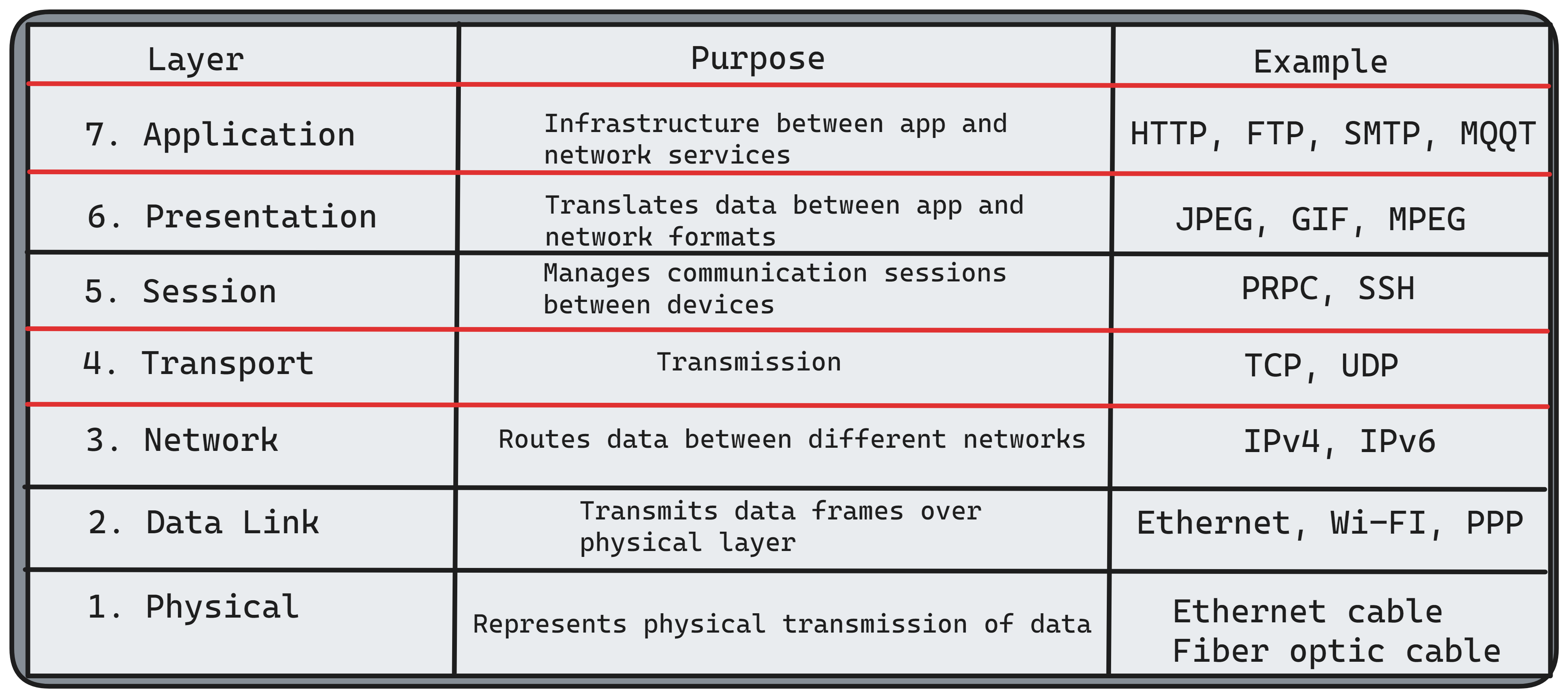
We will mostly focus on IP, TCP, and HTTP protocols today. Let's first remind ourselves what HTTP packets contain by looking at each of the protocols.
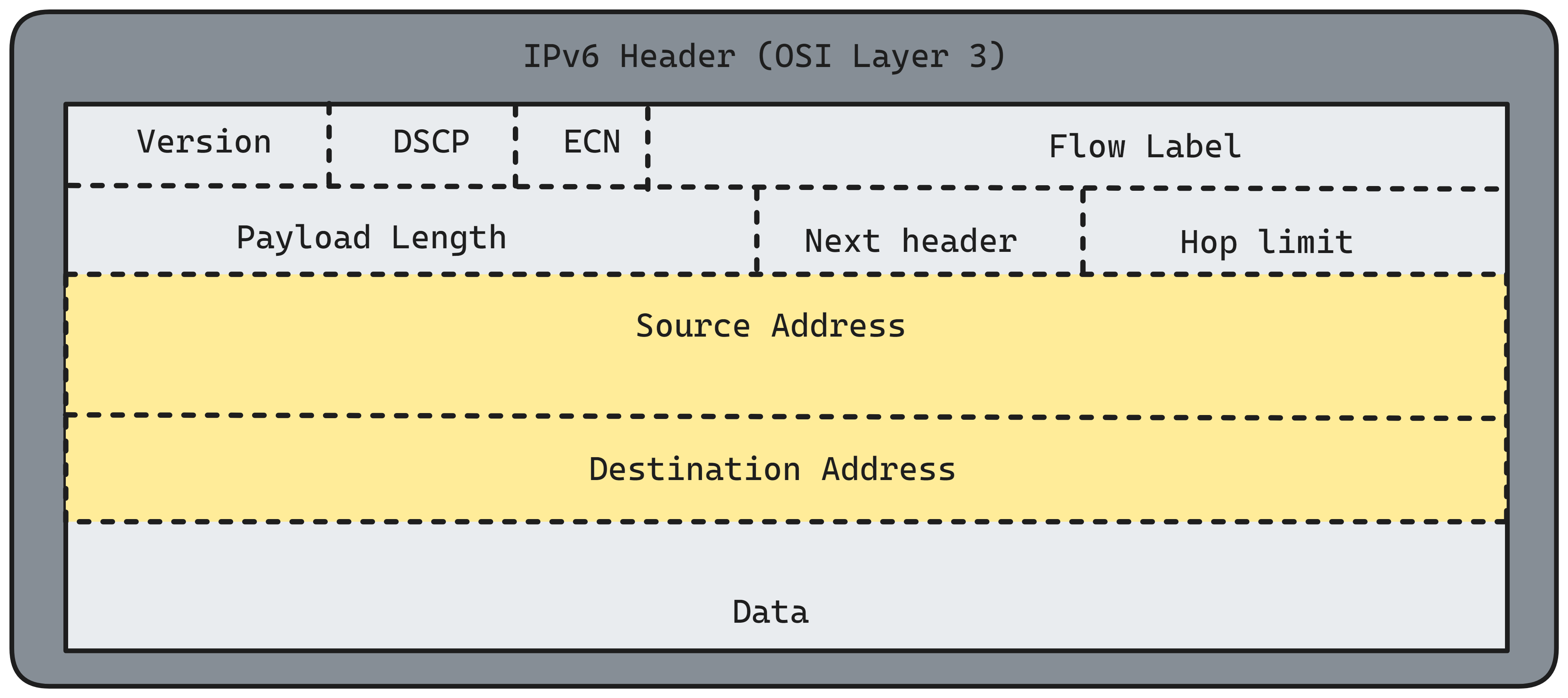
Looking into the IPv6 header for us what matters is the Source Address and Destination Address:
TCP on top of that has Source Port and Destination Port:
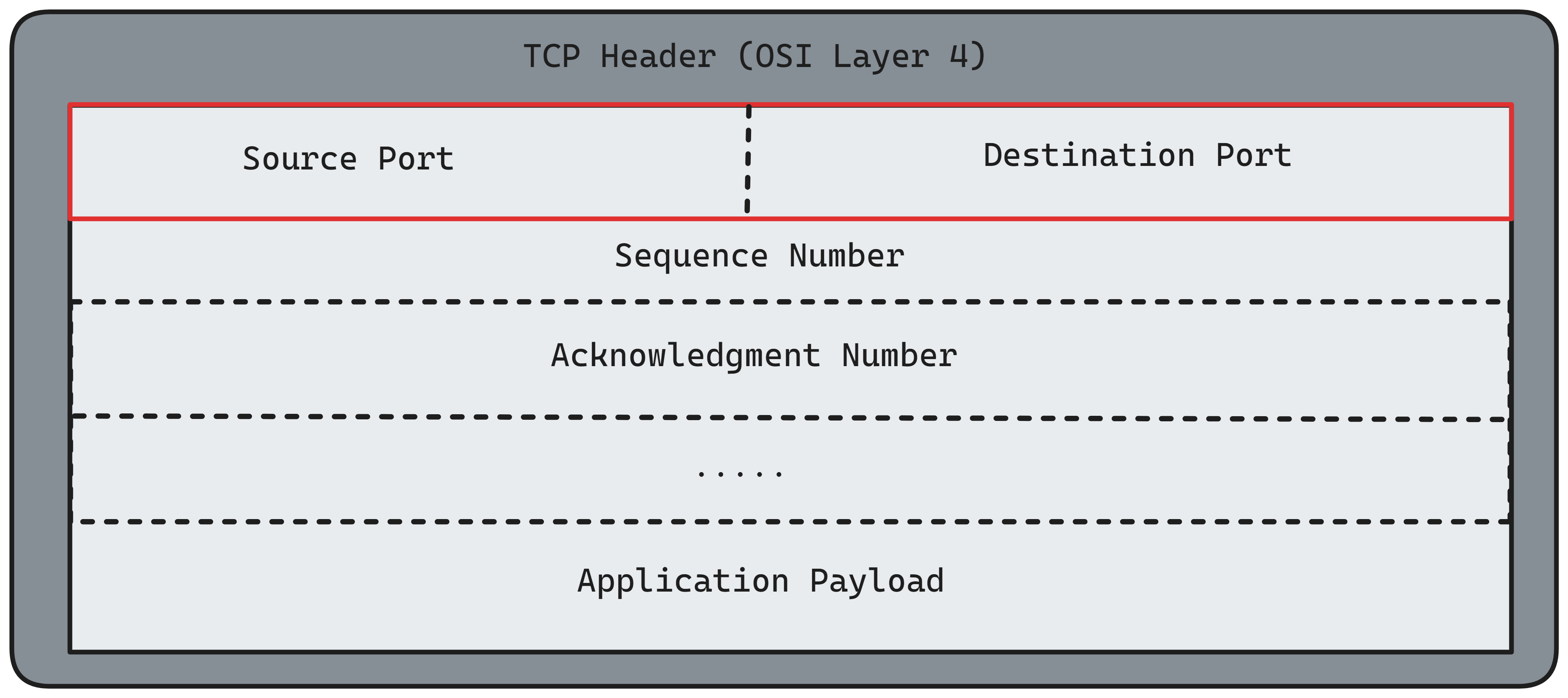

Altogether you have each higher layer encapsulating the lower OSI layer:
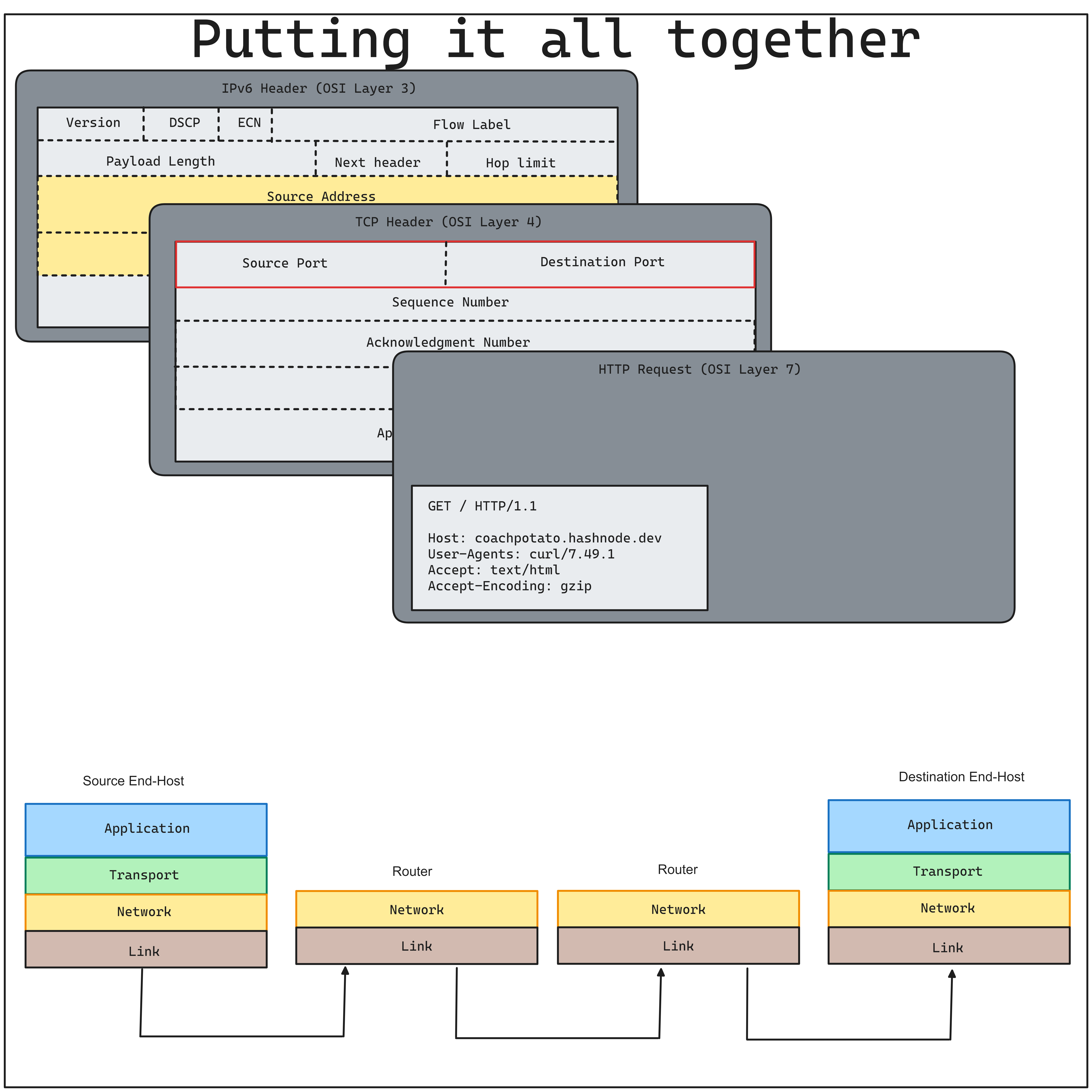
Now we have the foundation to move forward.
Layer 4 (L4) Load Balancer
Layer 4 load balancer decides what to do using the IP and port number, avoids extra network steps like checking data content, and can hide server addresses by mapping them to a single public (virtual) IP.
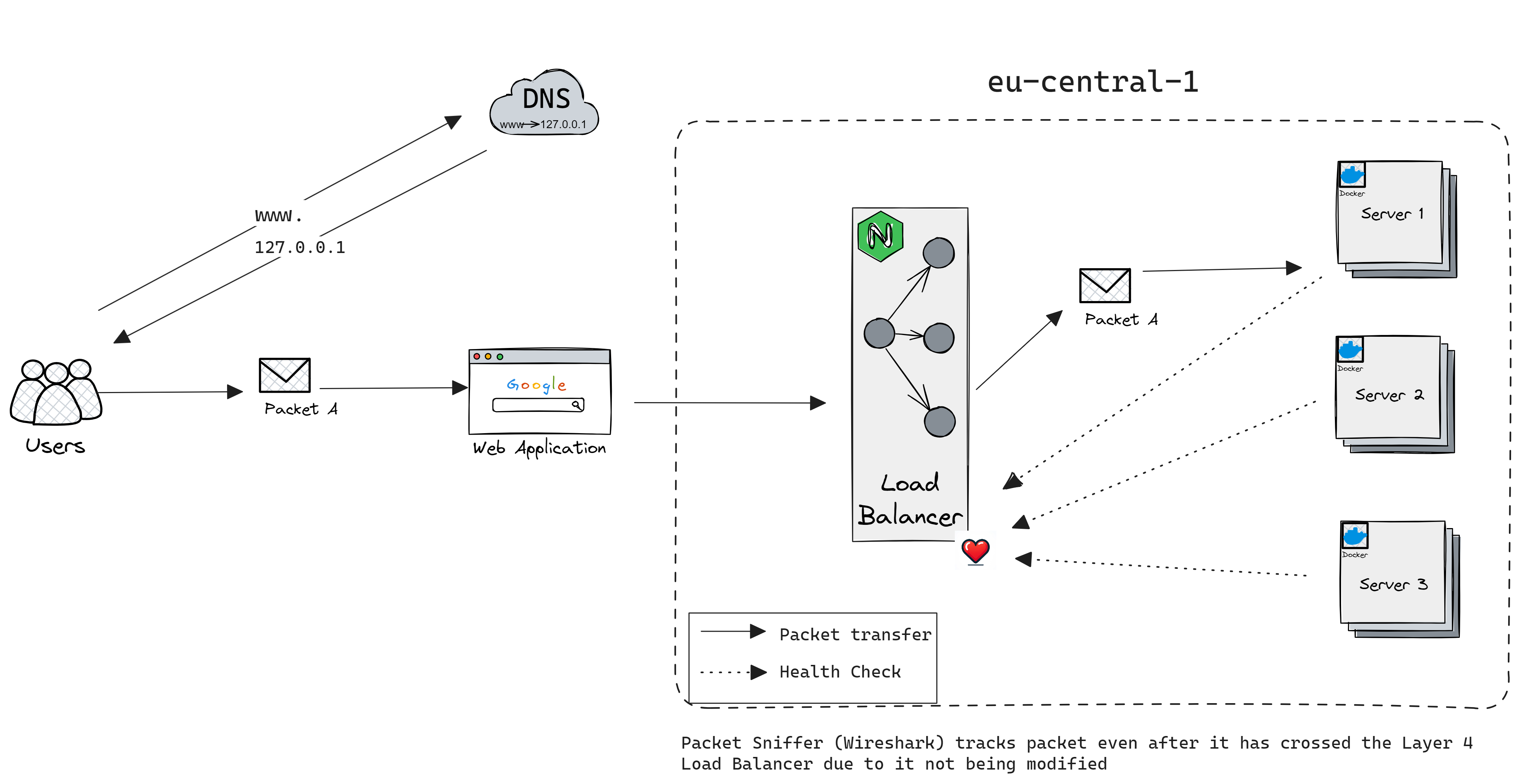
There are two main types of L4 load balancers: termination and passthrough load balancers.
TCP/UDP termination Load Balancers
In this type of load balancer, two TCP connections are established: one between the client and the load balancer, and one between the load balancer and the backend.
L4 termination load balancers are favored because:
They are relatively simple to implement.
Terminating connections close to the client reduces latency significantly. Placing the load balancer near clients allows for high-quality, fast optic fiber connections within your network, enhancing performance. Additionally, if the load balancer fails, most connections will already be terminated, minimizing overhead and potential issues with network sockets.
The important fact is that one machine can have millions of open connections at a time but there is no easy way to open a million collections in any reasonable time. So technically if the server fails there is the overhead of opening the connections again.
Before the termination of the connection, I assume the LB should store TCP data somewhere.
TCP/UDP passthrough Load Balancers
In this type of load balancer, the TCP connection is not terminated by the load balancer.
For this to work you will need:
Connection tracking: the process of keeping track of the state of all active TCP connections (whether the handshake been completed, how long the connection has been idle, which backend is selected for connection, etc)
Network Address Translation (NAT): the process of using connection tracker data to alter IP/port information of packets as they go through LB.

In this case, the L4 load balancer first establishes a TCP connection with backend servers.
It keeps the connections warm and neglects the need for a three-way handshake when the client connects to LB. Later when a client connects to L4 LB that connection would be mapped to one of the connections from backend servers. This means that all data packets within the TCP connection will end up going to only one connection on one server.
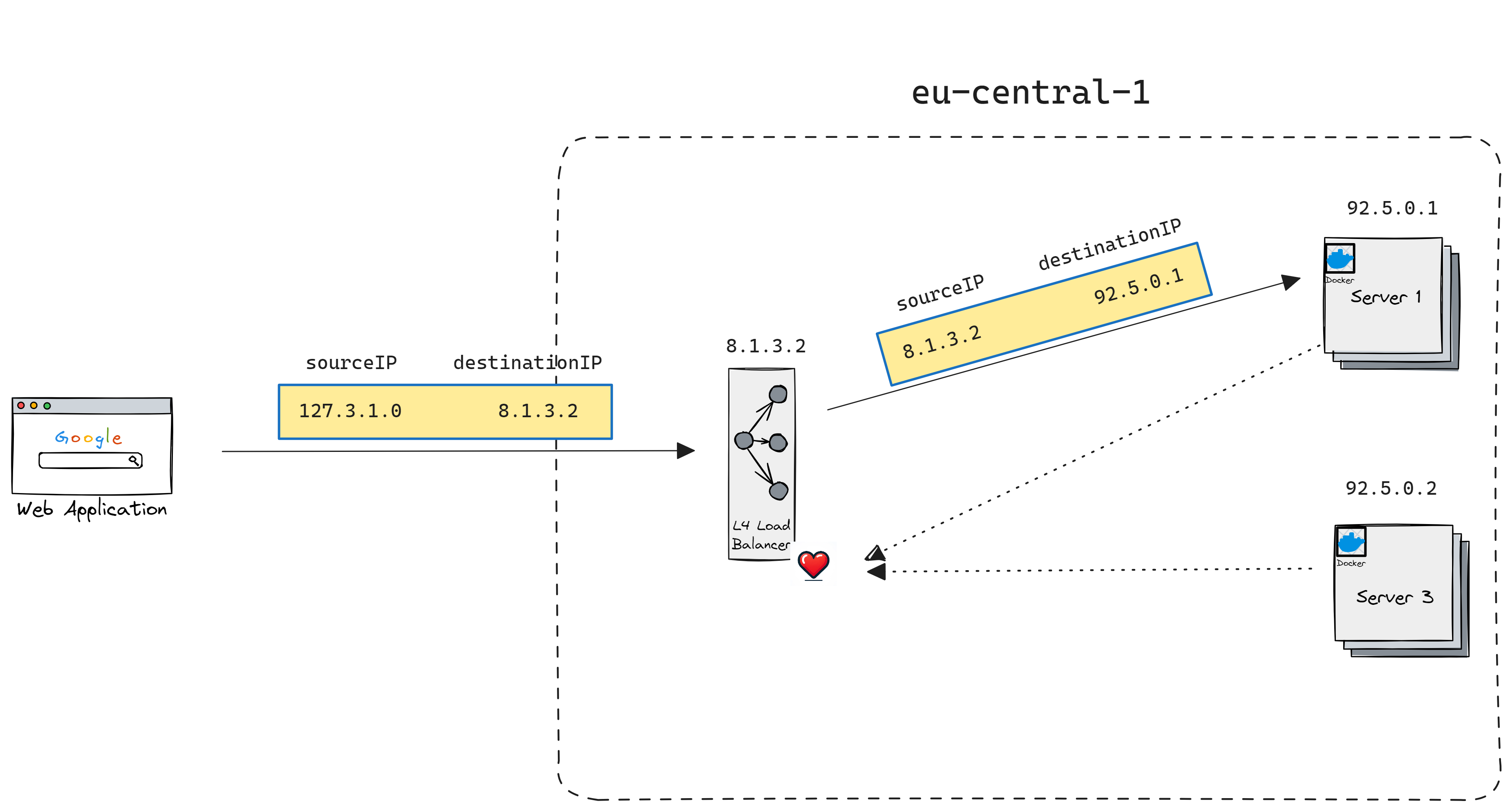
Main benefits of this approach are:
Performance and resource usage: passthrough LB are not terminating TCP connections. The amount of state stored per connection is quite small and generally accessed via efficient hash table lookup. Passthrough LB can typically handle a larger number of active connections and packets per second.
Allow backend servers to perform customized congestion control: as Load Balancer is not performing TCP termination.
It forms the baseline for Direct server return (DSR): passthrough load balancing is required for DSR and clustering with distributed consistent hashing.
Direct Server Return (DSR)
DSR builds upon the passthrough load balancer concept discussed earlier. It optimizes by allowing only request packets to traverse the load balancer, while response packets bypass it and travel directly back to the client. This approach is particularly compelling because, in many scenarios, response traffic far outweighs request traffic, such as typical HTTP request/response patterns.
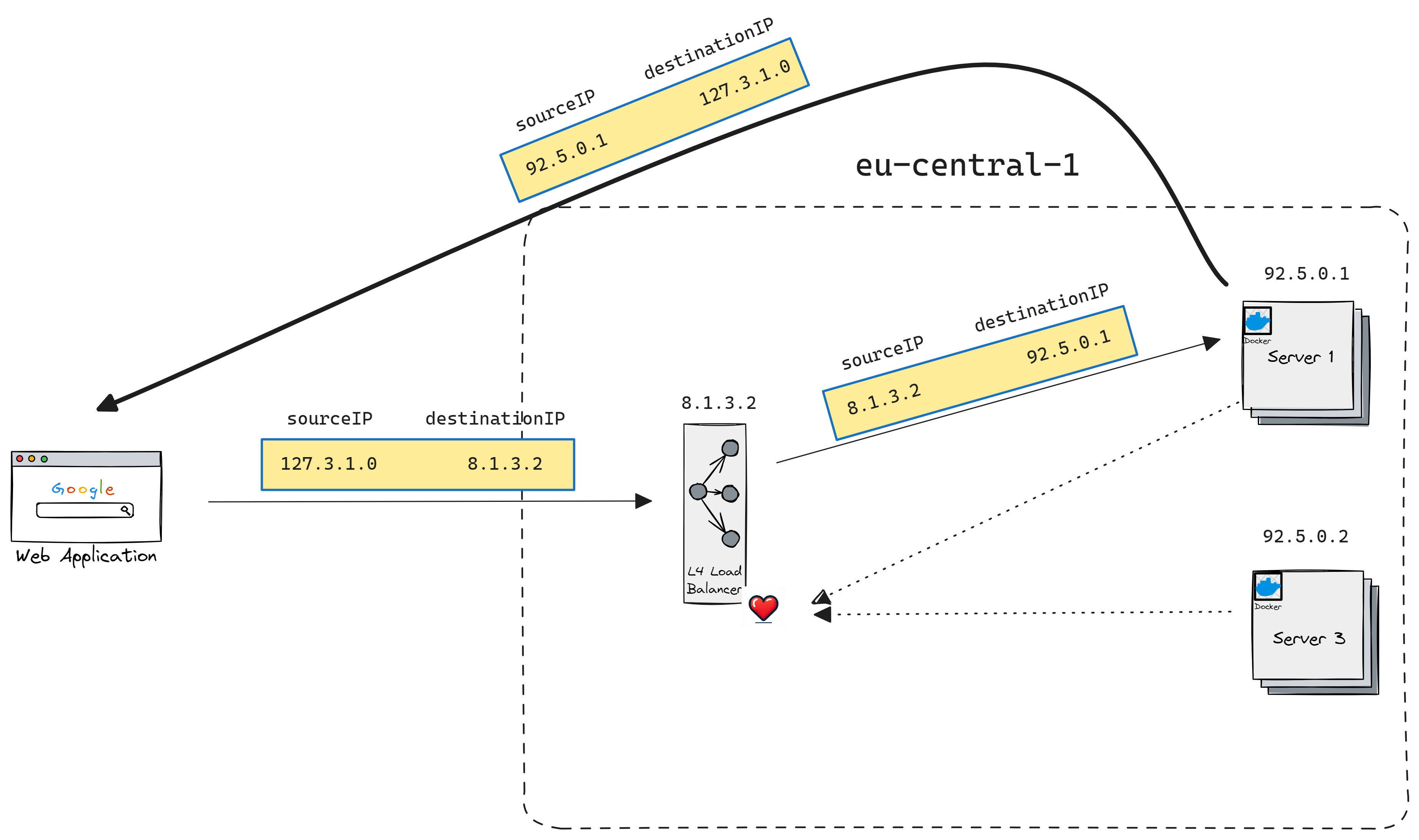
Conclusion
As a general rule of thumb, L4 LB is used anywhere where the application behind the balancer doesn’t work over HTTP(S):
SMTP, WebSockets, UDP-based, etc
Database servers
Message brokers: MQTT (RabbitMQ), TCP (Kafka)
or as a gatekeeper when routing data from the client to the entire cluster (common topology based on engineering blogs). Also as it works on TCP/UDP it is agnostic to higher-level protocols. An additional benefit of the L4 load balancer is that it does little to no packet manipulation, therefore output is almost identical to the input. The main advantage of this is that LB can use hardware more efficiently (integrated controllers, ASICs), and as a bonus side effect, it makes troubleshooting much easier.
As a disadvantage, L4 load balancers can't do intelligent traffic distribution and they don't support intelligent rate-limiting, operation blocking by HTTP layer data. Also, you can't do much caching as there is not much to cache on Layer 4.
As an additional read, you can check this problem with UDP load balancing.
Layer 7 (L7) Load Balancer
A layer 7 load balancer operates at the application layer, specifically dealing with HTTP and HTTPS traffic. It terminates incoming network traffic to read and interpret the data within, such as URLs, HTTP headers, and cookies. This allows it to make sophisticated decisions on how to route traffic based on the content of the messages.
One of its capabilities includes SSL termination, which is the process of decrypting secure traffic. However, this requires managing SSL certificates, meaning you can't place a layer 7 load balancer directly after DNS resolution without handling these certificates, which complicates its deployment.
The discussion about whether SSL/TLS encryption falls within layer 7 is ongoing, but for our purposes, we consider it part of layer 7 functionalities. This ability to terminate SSL is double-edged; it provides advanced routing capabilities at the cost of additional certificate management.
Layer 7 load balancers address a key challenge that layer 4 load balancers (which route traffic based merely on IP address and port number): uneven traffic distribution. For example, if two clients are connected through a layer 4 load balancer, and one sends significantly more data than the other, the server handling the busier connection will be under a much greater load, which defeats the purpose of load balancing. This is exacerbated by protocols that allow for multiple requests over a single connection or keep connections open even when not actively being used, leading to potential imbalances in server load.
Layer 7 load balancers solve this issue by intelligently routing individual requests or streams within a single connection to different backend servers. For instance, in an HTTP/2 connection, which supports multiplexing (multiple requests over a single connection) and keep-alive (persistent connections), a layer 7 load balancer can distribute the requests across multiple servers. This ensures that even within a single, high-traffic connection, the load is spread evenly across the backend, preventing any single server from being overwhelmed and maintaining the effectiveness of load balancing.
WebSockets
WebSockets offer a push-based method, serving as an alternative to HTTP long polling, where the client continuously requests data from the server and waits for a response until new data is available or a timeout occurs. Unlike long polling, which is resource-heavy due to its pull-based nature and the need for opening new connections repeatedly, WebSockets establish a single, continuous connection for real-time data exchange, reducing the overhead and resource consumption.
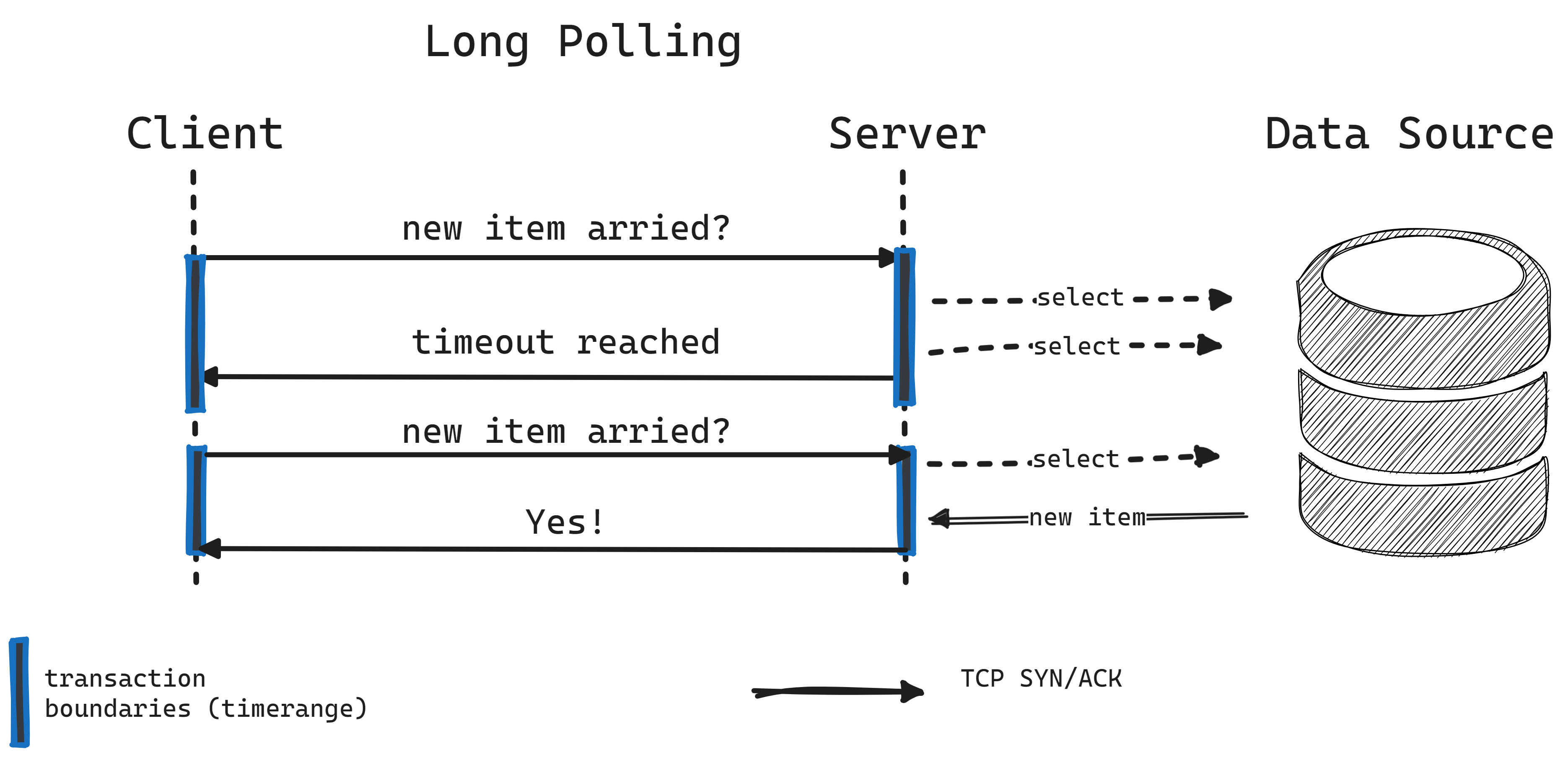
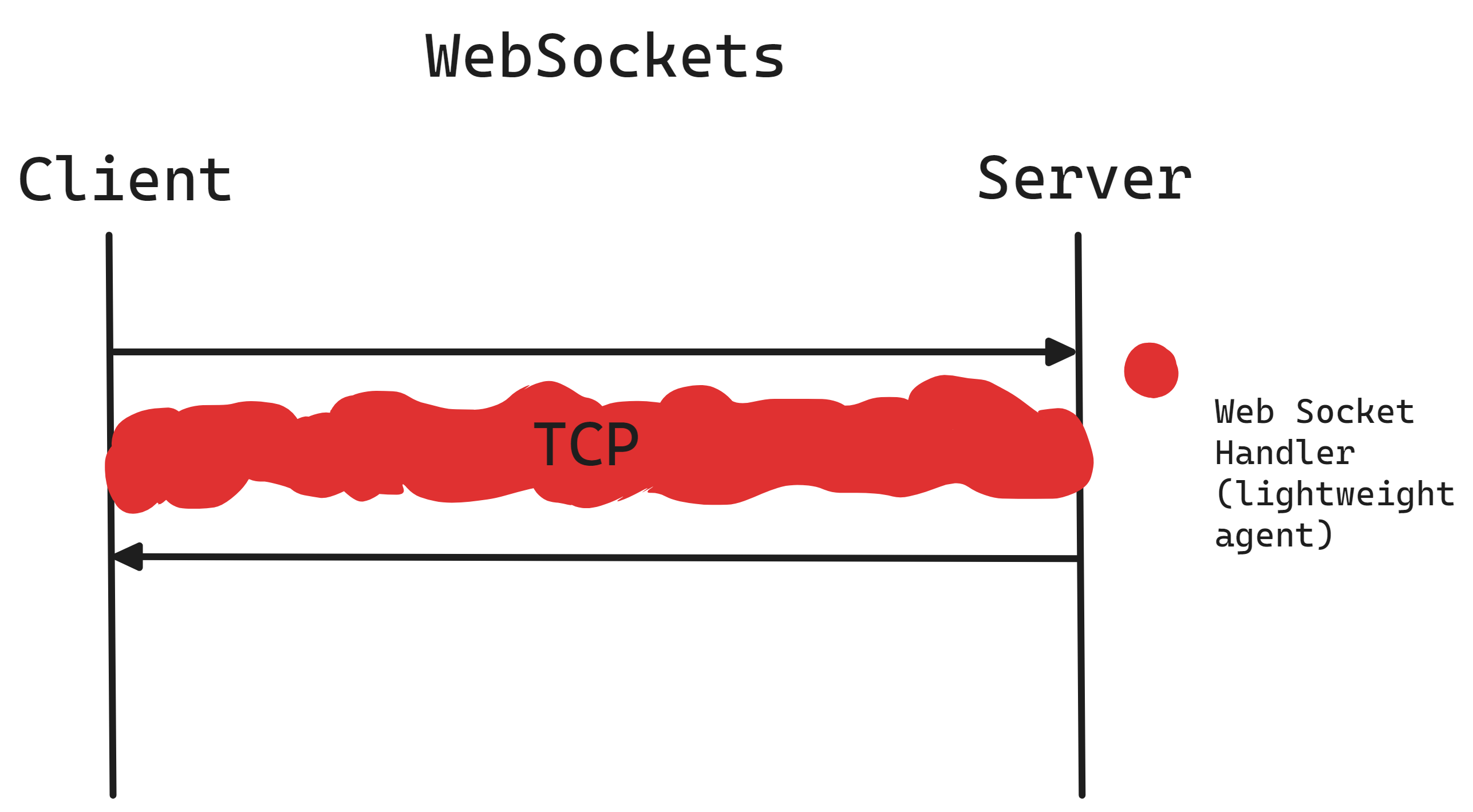
WebSockets facilitate two-way, message-based communication of both binary and text data between a server and a client, as outlined in RFC 6455.
This differs significantly from HTTP, which is designed for brief data transfers. Since many load balancers default to closing idle HTTP connections quickly—often after 60 seconds—to manage resources efficiently, they might inadvertently disrupt long-lasting WebSocket connections. To maintain these persistent connections essential for WebSocket communication, it's necessary to adjust the load balancer's settings to extend the timeout period beyond the default, allowing for continuous, uninterrupted sessions.
Integrating WebSockets introduces a unique set of challenges, often requiring a split architecture where parts operate over HTTP and others utilize WebSockets. Unlike HTTP, where load balancers can terminate connections, WebSocket connections are continuous and thus cannot be terminated in the same manner. This means your servers need to manage some level of state to handle the ongoing interactions. To efficiently route traffic from the load balancer to the appropriate backend servers, session affinity becomes a crucial strategy. This approach ensures that connections from a particular client are consistently directed to the same server, facilitating a stable and persistent communication channel necessary for WebSocket's real-time capabilities.
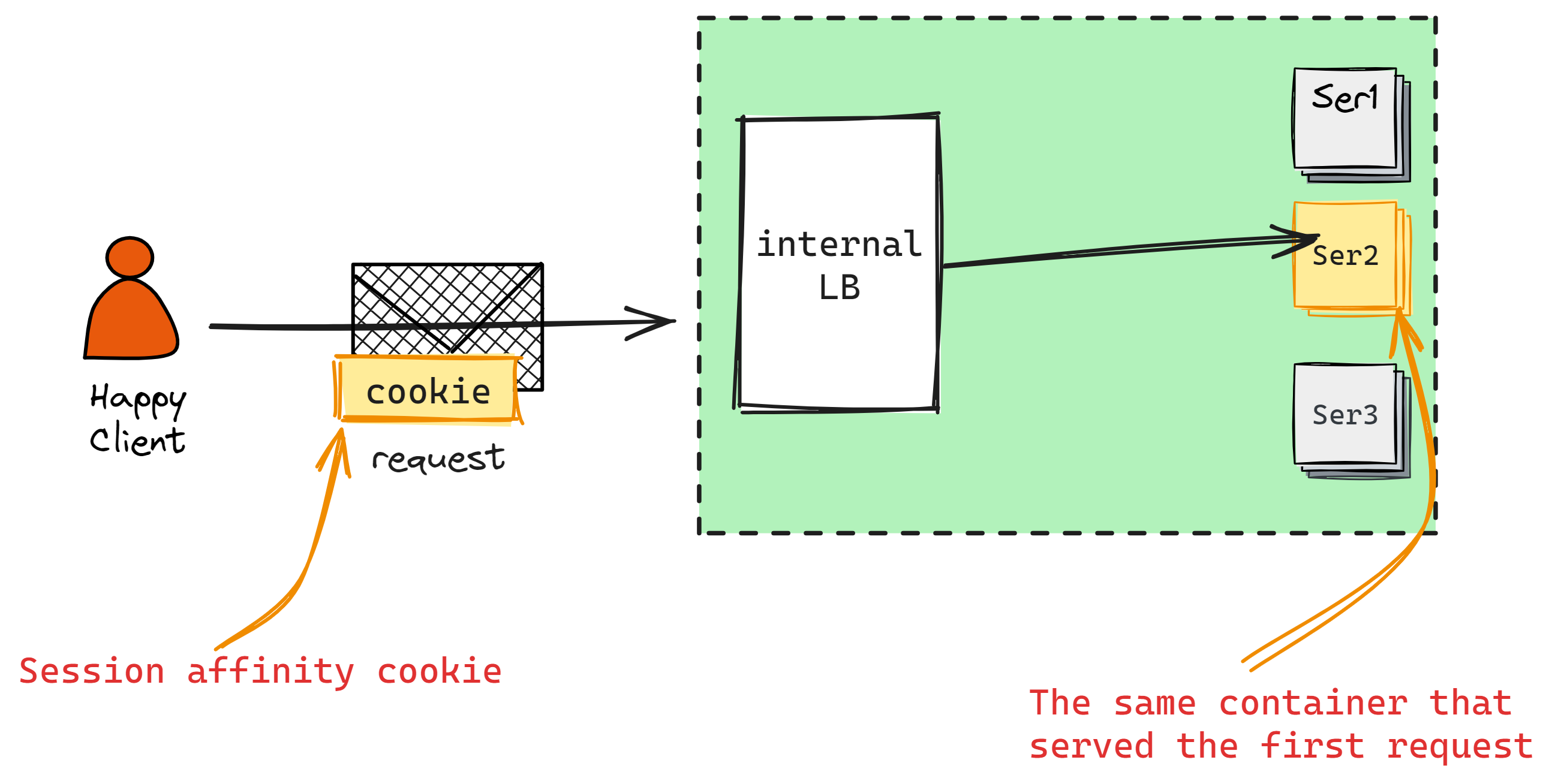
Note that session affinity (sticky session) is inherently fragile as in case of server failure, to mitigate some of the risks you can consider storing session data in a centrilized cache (Memcache, Redis) however, it has its tradeoffs.
Here is a great video on embracing failure from Jeffrey Richter Architecting Distributed Cloud Applications. The main idea is very simple: try to have stateless servers if you can.
Another problem with WebSockets is in its nature: long keep-alive connections peer-to-peer.
Let’s say you have two servers and two WebSocket connections:
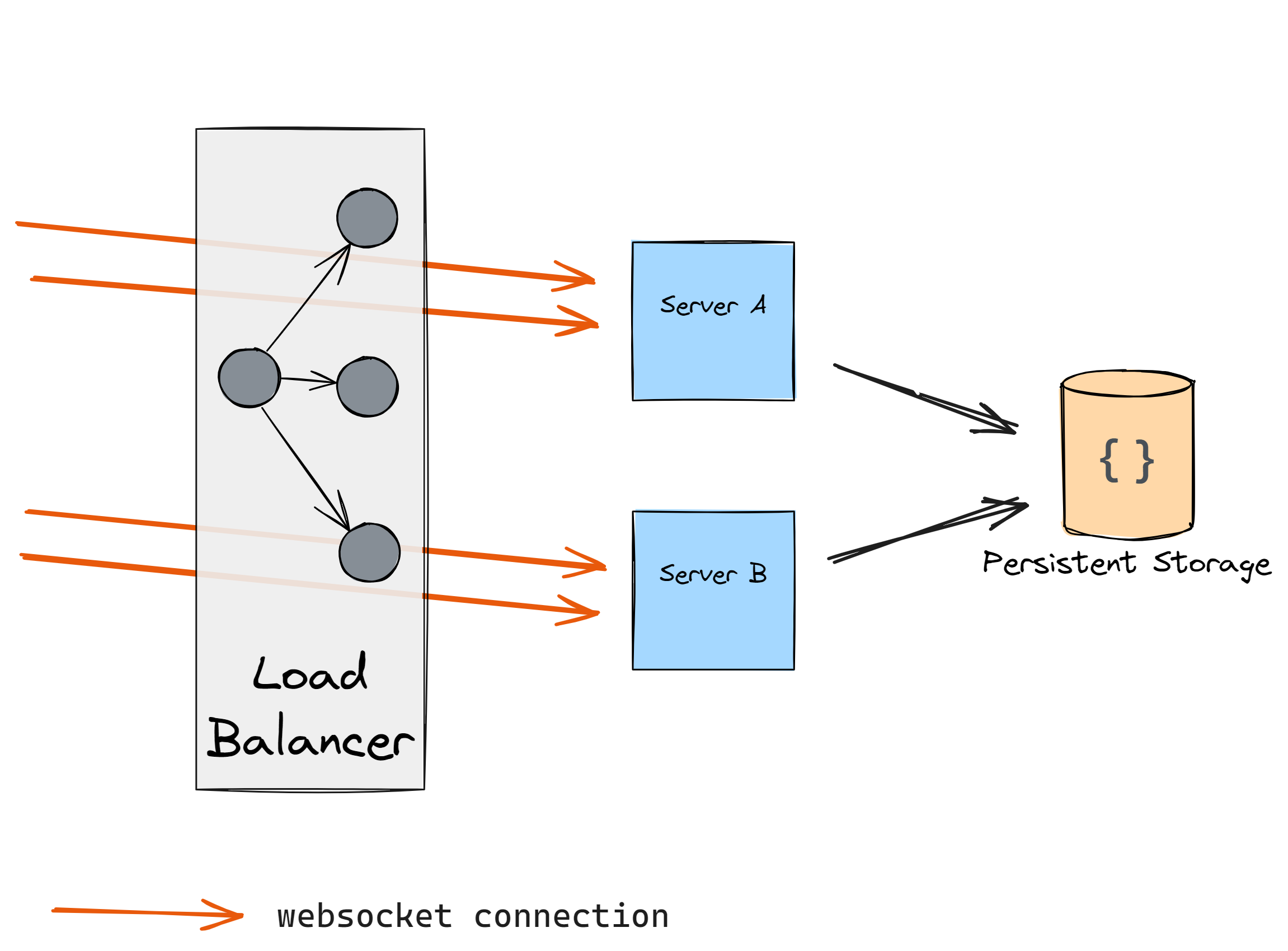
After some time you notice that the load is a bit too high so you decide to add another server:
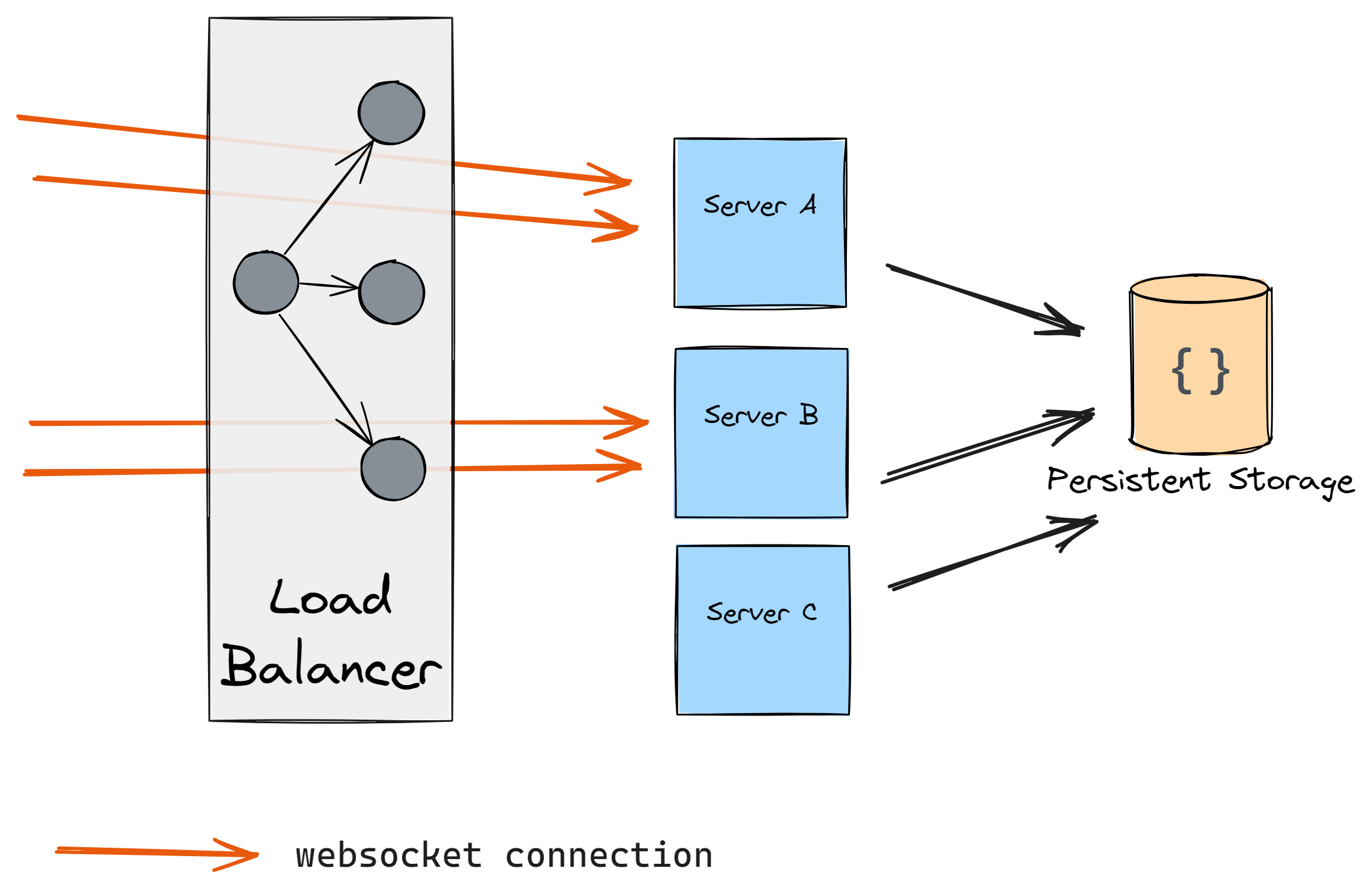
However, as connections are kept-alive you don’t get any traffic to the new server. So what do you do? You restart the previous two servers hoping that the load will be distributed, however, this happens:
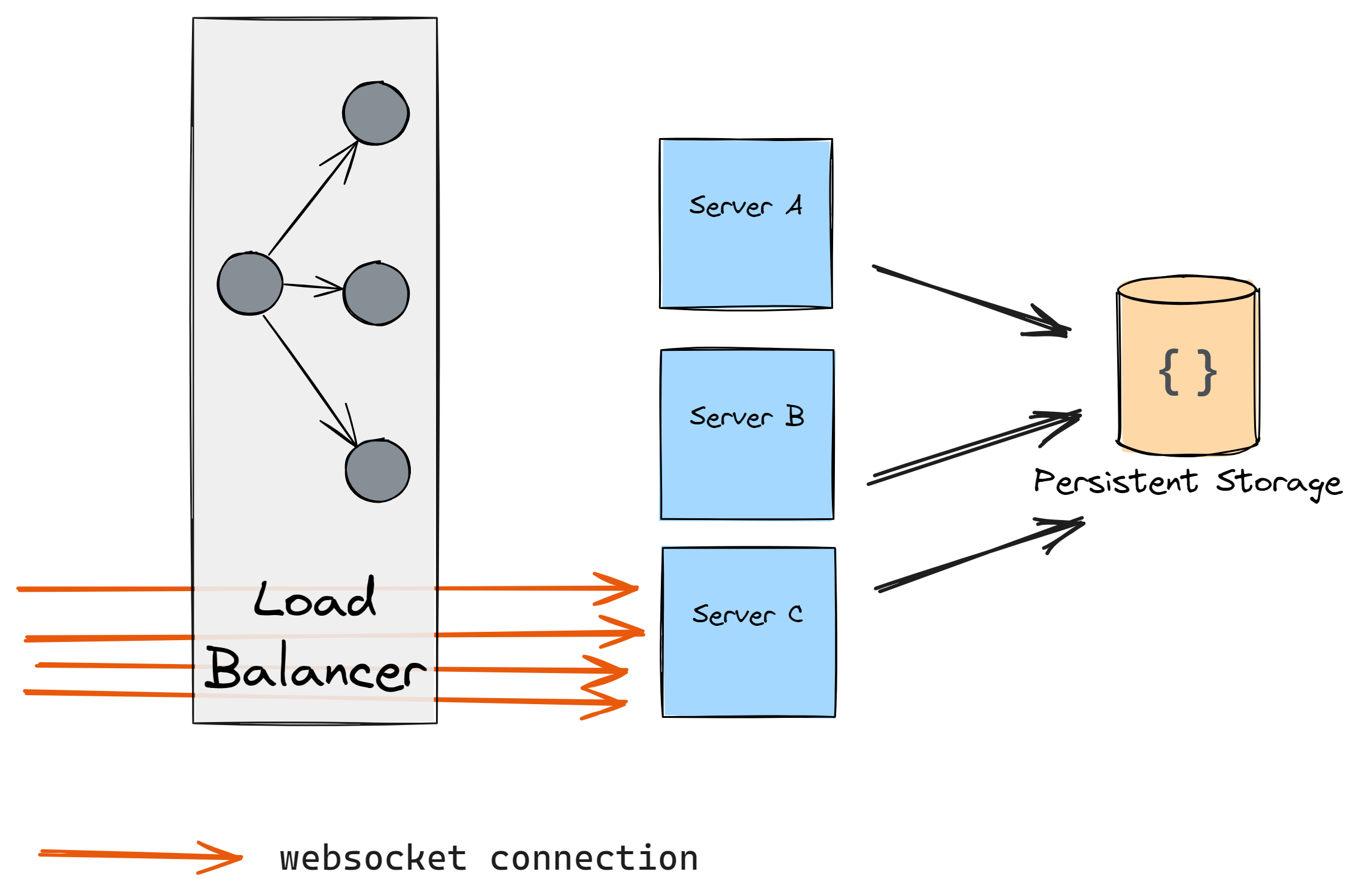
The cloud providers' load balancers mitigate this issue however with the on-premise setup it can be a challenging task to solve.
Global Server Load Balancer (GSLB)
Global Server Load Balancers (GSLB) distribute internet traffic across multiple data centers or servers worldwide. They use DNS-based load balancing to direct clients to the closest or least busy server, ensuring efficient traffic management. GSLB also monitors the health and performance of servers across different regions to maintain high availability and support disaster recovery strategies. This technology is crucial for services requiring consistent uptime and quick access. Examples of GSLB solutions include F5 BIG-IP and Akamai GTM.
DNS Load Balancer
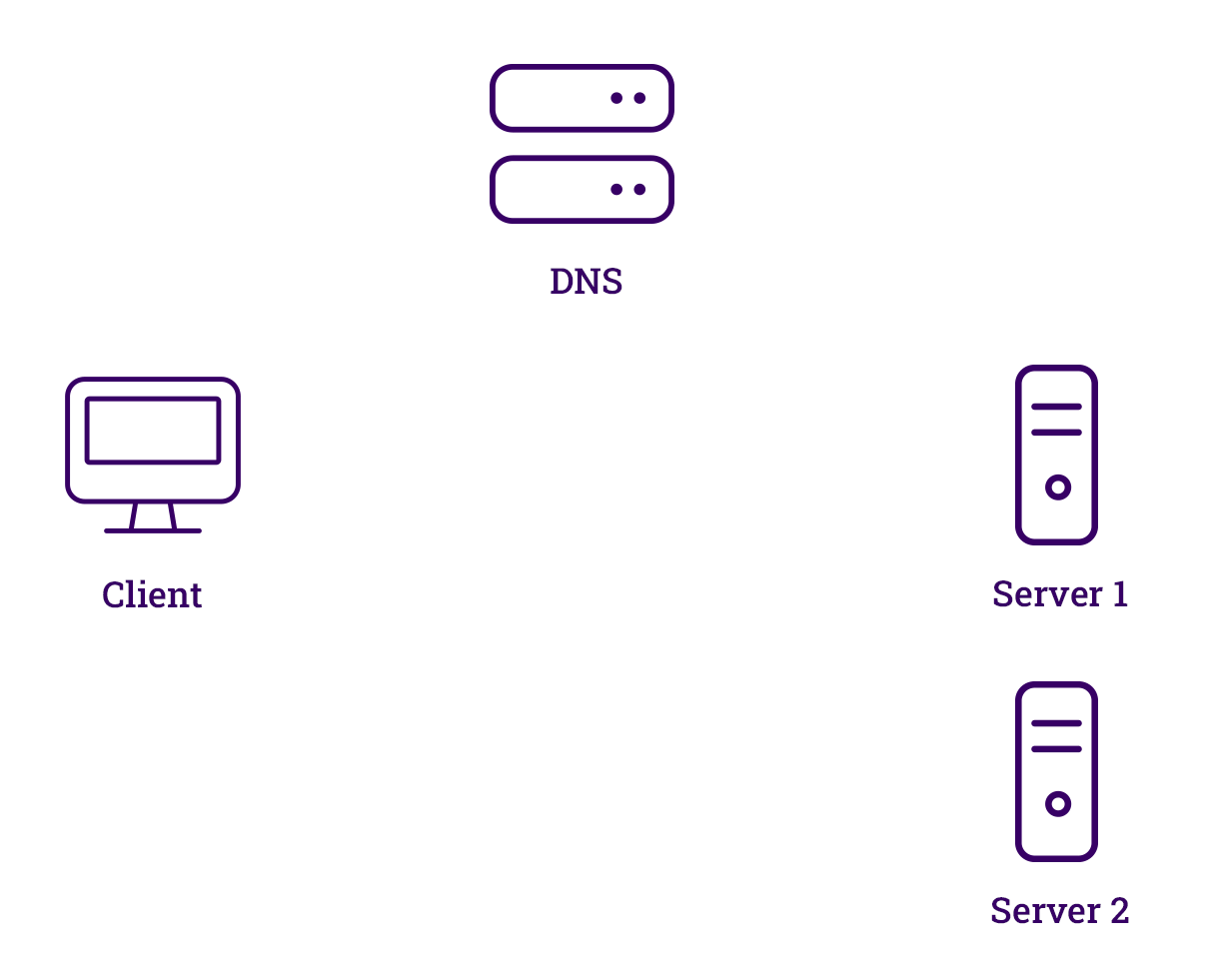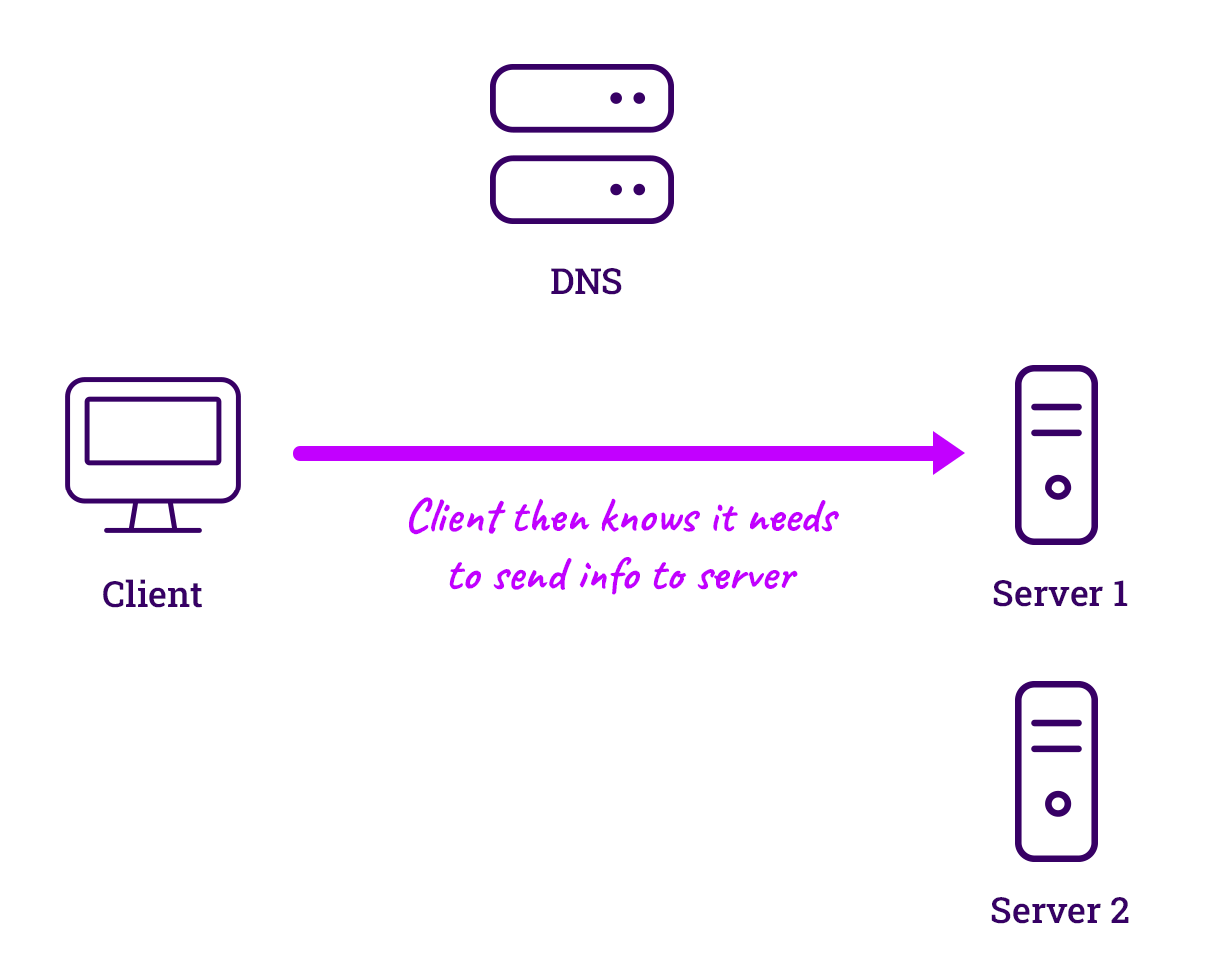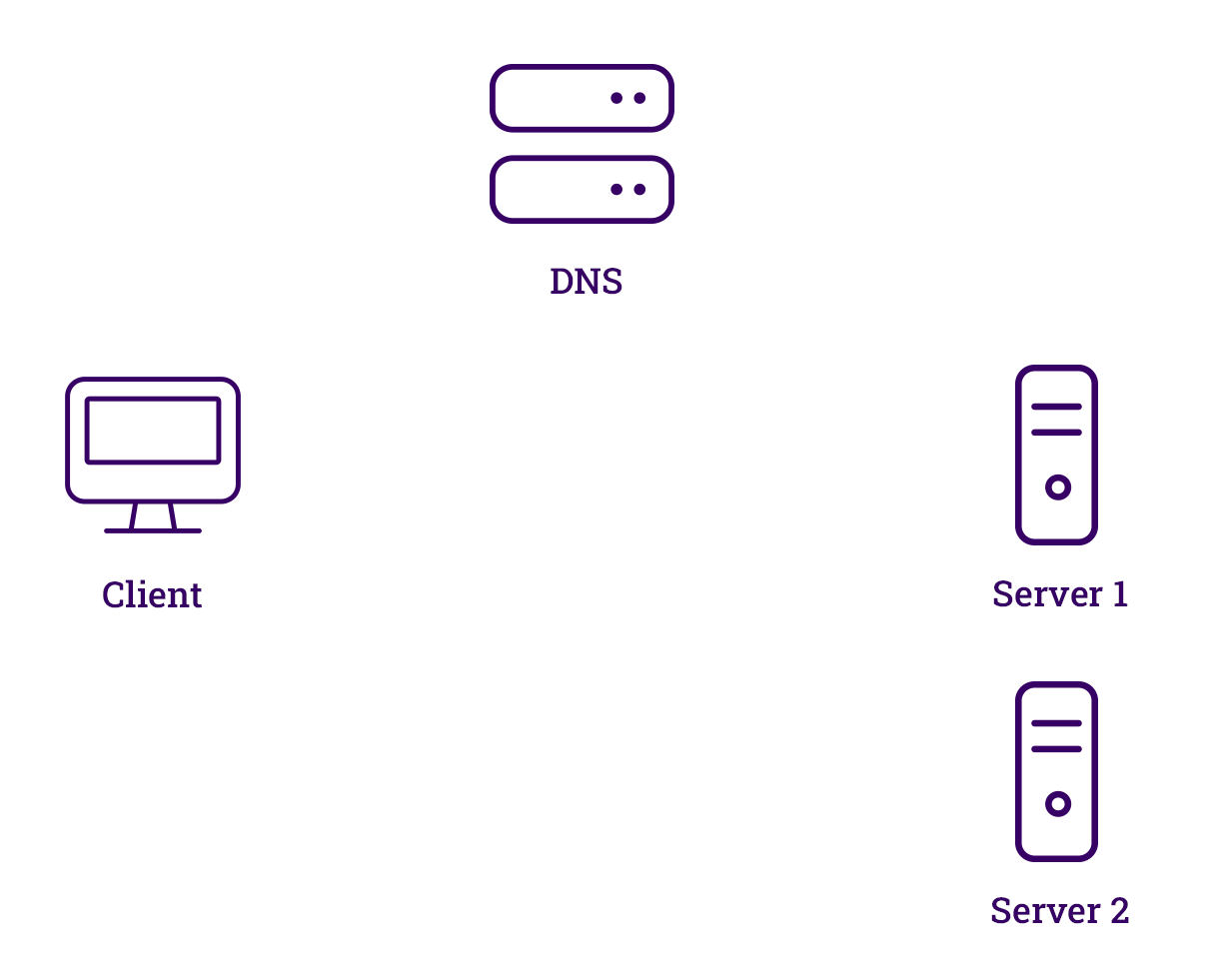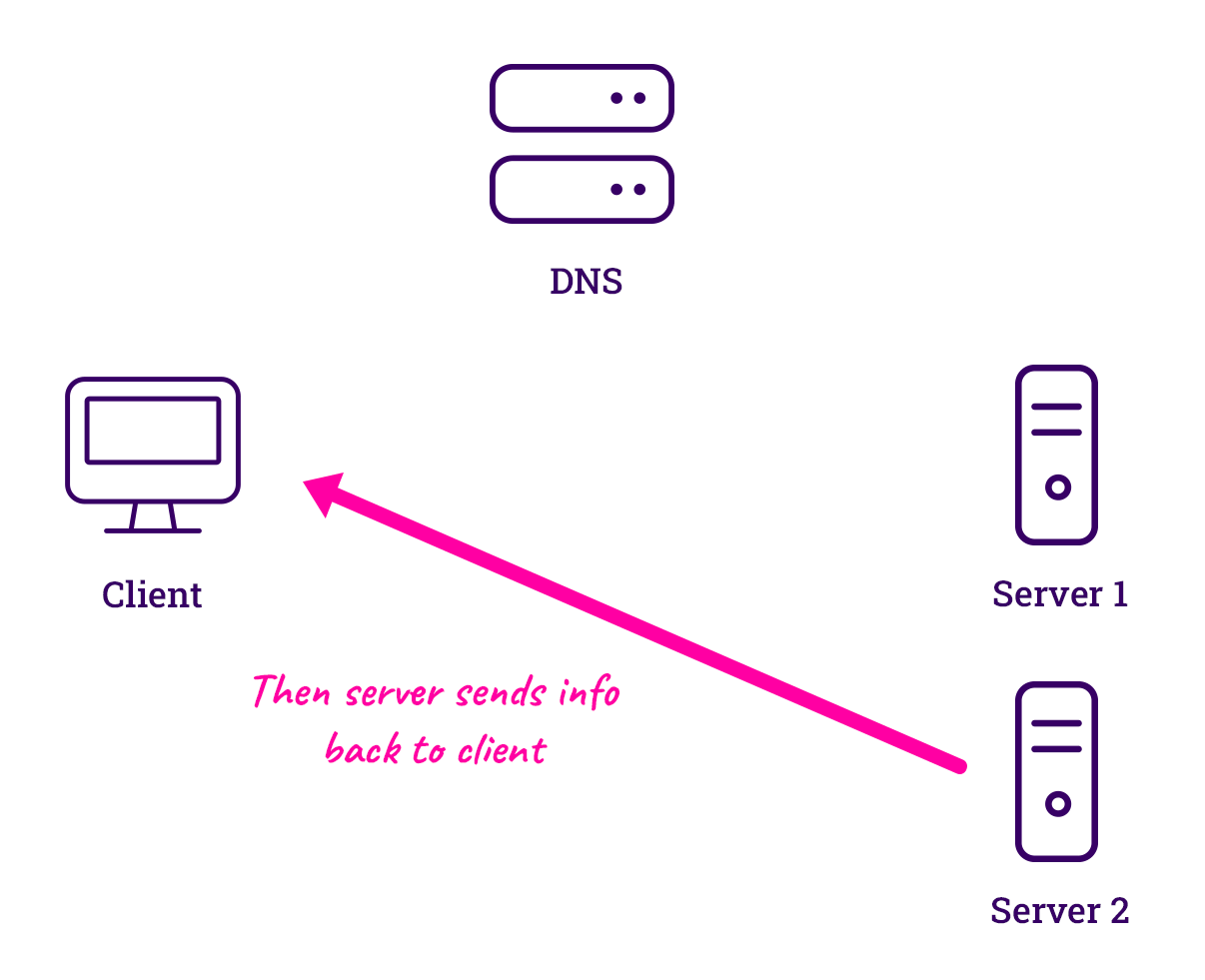
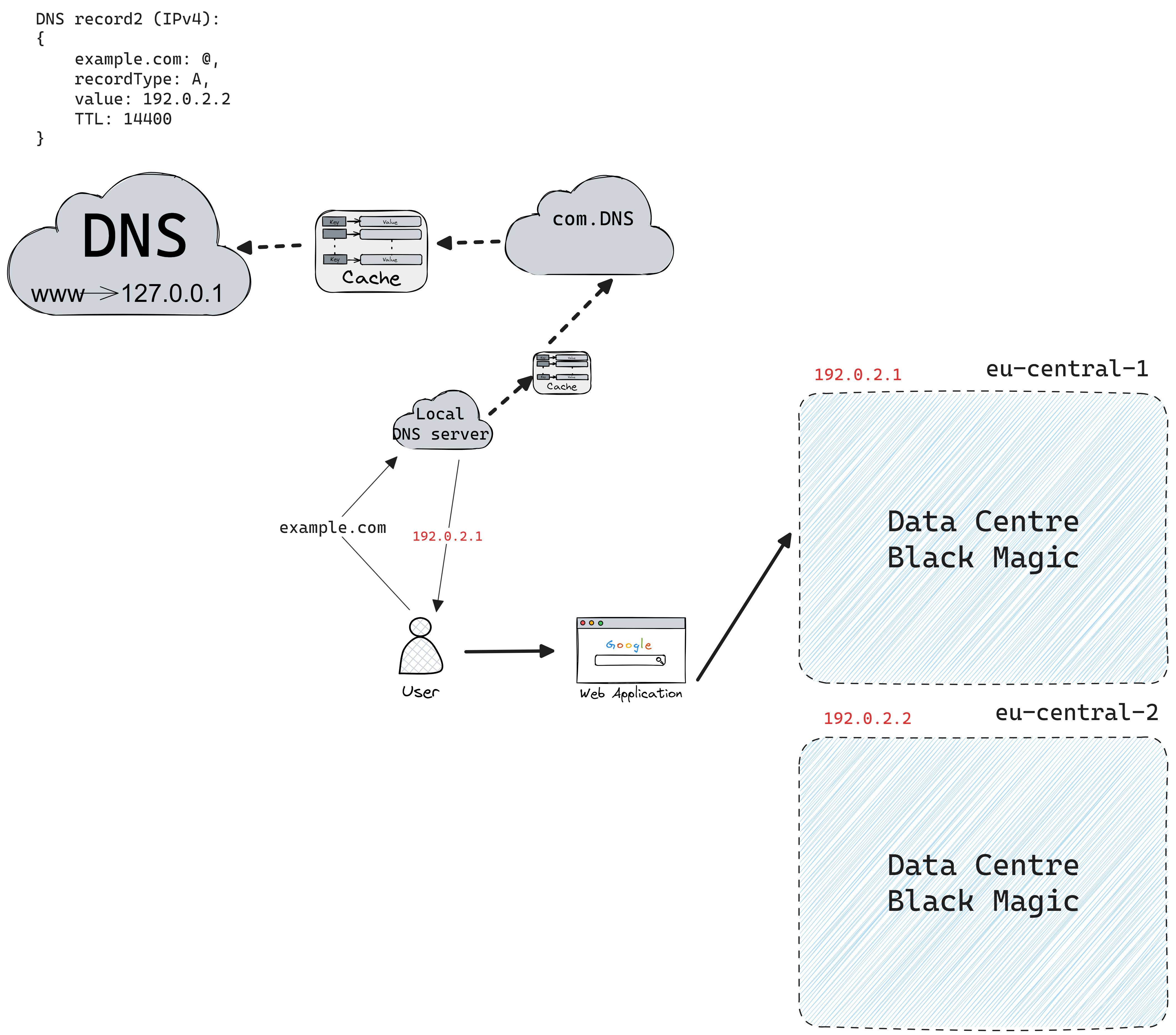
DNS load balancing works by using DNS servers to connect domain names with not just one, but multiple IP addresses. Each of these addresses points to a different server that's part of a bigger group of servers. This way, if one server goes down, DNS can quickly switch to another one by changing the addresses it gives out, keeping everything running smoothly. This switch is done by monitoring the servers with tools or by watching how real users interact with them, and then picking the best server accordingly.
However, there are some downsides. The main issue is that DNS information is often stored for a set period (TTL or time-to-live), and changes only take effect after this time runs out. Also, when DNS gives out these addresses, it doesn't control which one gets used next—it could be random or in a set order. It doesn't know which server is closest to the user, either, but using a method called anycast can help with this. Lastly, there's a limit to how much information DNS can send at once, which is set at 512 bytes by a rule known as RFC 1035.
Service Discovery and Health Checks
Service discovery is the process by which a load balancer determines the set of available servers (backends). There are a few ways to do service discovery:
Static/dynamic configuration files. While static configuration files are just a dictionary of available servers, dynamic configuration is based on calling external service registries or servers directly (/health-check).
DNS resolution. Each service deployed within the cluster gets its own DNS entry. Load balancers can resolve these DNS entries to discover available instances of the service and distribute traffic accordingly.
Service Registry, Service Mesh
Zookeeper, Consul, Etcd, etc
Service discovery and its configuration for LBs pose significant challenges.
Here are just a few examples of outages related to wrong LB configuration: Slack, Amazon -> Netfix Xmas Even Outgate.
Health checks are like regular check-ups for servers to make sure they're working properly and can handle incoming requests, which helps keep websites and applications running smoothly without any interruptions. There are two main ways to do health checks:
Active: ping the server regularly on
/healthPassive: LB detects health status from the data flow. As an example, L4 LB might decide that the server is unhealthy if there have been three connection errors in a row. L7 LB might decide that the server is unhealthy if there have been three HTTP 503 response codes in a row.
Algorithms
We aim to spread our internet traffic evenly across different data centers and servers in the best way possible. But what do we mean by "best"? Well, the best approach changes based on several things:
Whether we're looking at the problem from a wide (global) or narrow (local) view.
Whether we're considering the technical aspects (like software vs. hardware).
The type of internet traffic we're handling.
Let's look at two examples: searching for something online and uploading a video. When you search, you want quick answers, so speed (latency) is key. For uploading videos, it's okay if it takes a bit longer, but you want it to work on the first try, meaning the ability to handle a lot of data (throughput) is most important.
How we spread out these requests matters a lot:
Search requests go to the closest data center, measured by how fast it can respond (round-trip time), to keep things fast.
Video uploads might take a less busy route, even if it's a bit slower, to handle more data without delays.
On a smaller scale, inside a single data center, we usually treat all computers as equally close and connected. Here, we focus on using resources efficiently and preventing any single computer from being overwhelmed.
We're simplifying things, of course. Other factors might include choosing a slightly farther data center to keep the information ready to go (keeping caches warm), saving money, or using servers tailored to what users like.
We've already mentioned how sticky sessions work. Let's dive into other methods too.
Random
Requests are distributed randomly among the available servers without considering their current load or capacity.
Pros:
Simplicity.
Fair distribution over time.
Low overhead.
Pretty effective in stateless applications.
Cons:
No consideration of server load.
No session presence.
Ineffective resource utilization.
Limited control.
Round Robin
Requests are distributed sequentially to servers in rotation. It's simple and ensures an even distribution of load, but doesn't consider server load or response times.
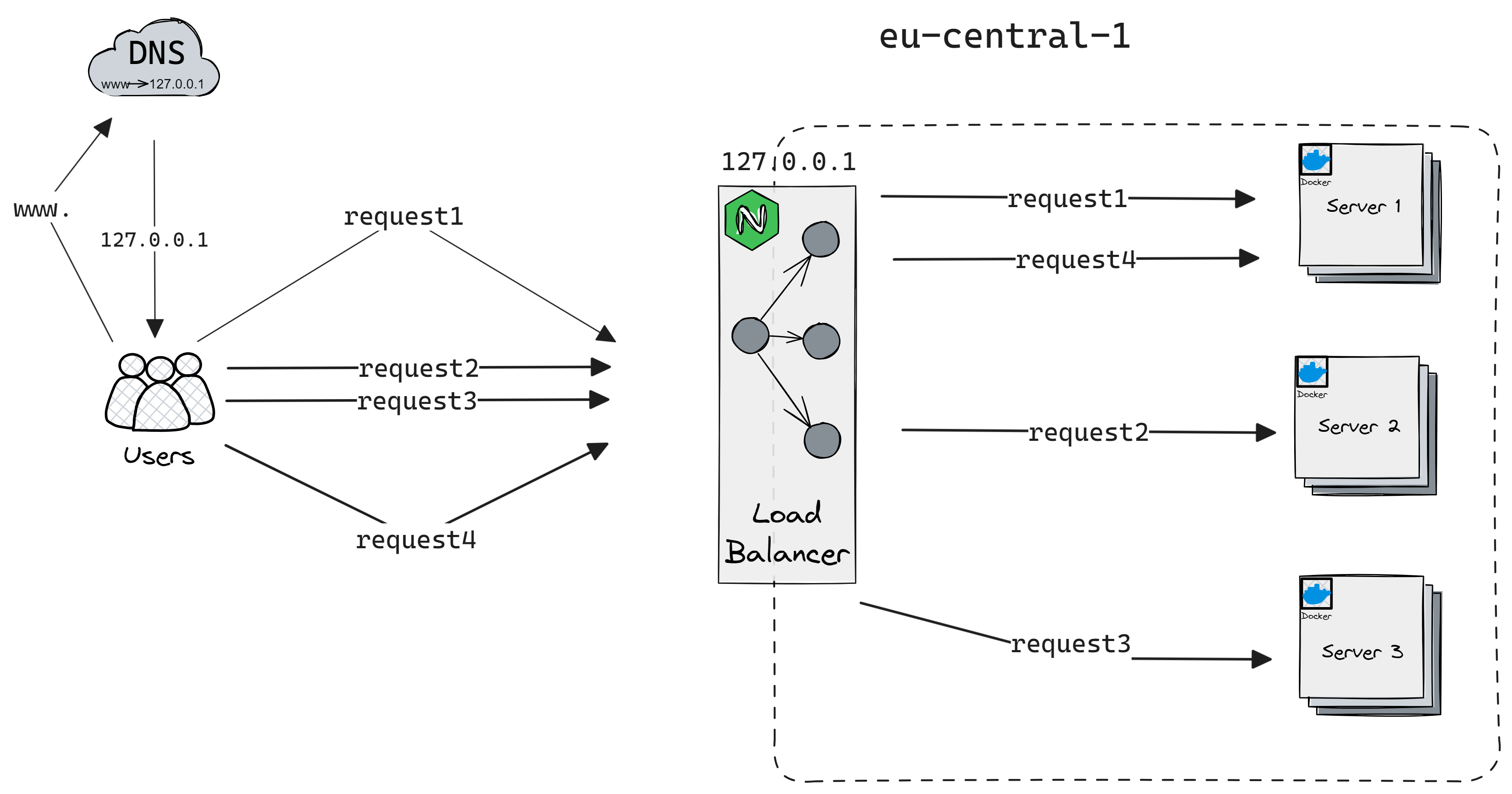
Pros:
Simplicity and ease of implementation.
Predictability and even distribution.
No need for monitoring.
Cons:
Ignoring servers load and capacity.
Ineffective with persistent connections.
Overloading potential.
Won’t work with stateful applications.
Least Connection
Requests are directed to the server with the fewest active connections.
This option is useful for incoming requests that have varying connection times and a set of servers that are relatively similar in terms of available computing and other resources. This is a good approach as the same user will get to the same server, which may be a need for WebSockets two-way communication.
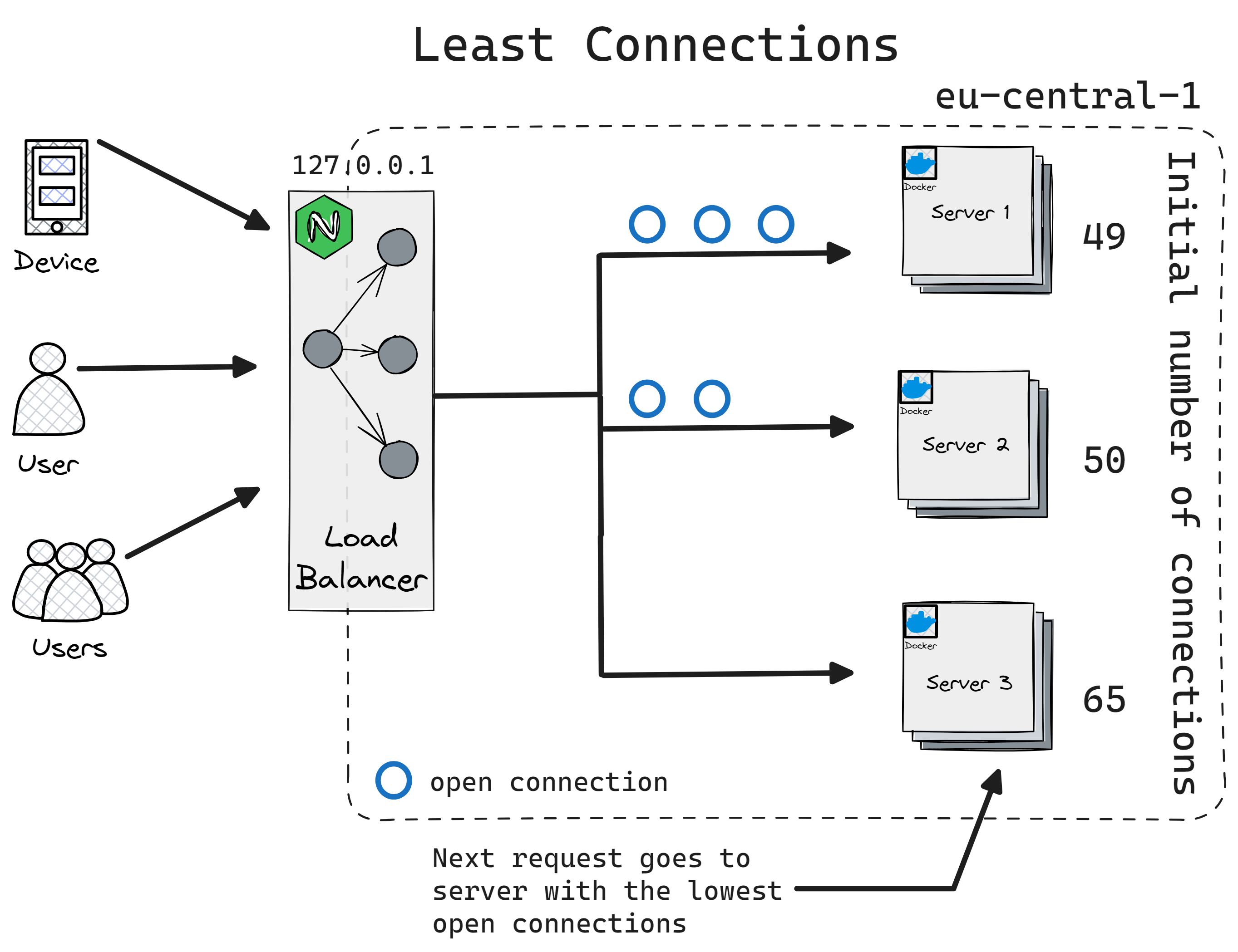
Pros:
Adaptive load distribution.
Improved resource utilization.
Responsiveness to real-time server performance.
Reduce server overload risks.
Compatible with sticky sessions.
Cons:
Your load balancer usually does not know anything about other load balancers or other external connections. In that case, you may be biased towards your local minimum.
Dangerous: the failing servers may start having fewer connections at scale as they will quickly return an error status code. Returning errors usually is much faster than processing a request.
No consideration of server load.
Stateless so you can’t take into consideration the historical load or the context of request. Doesn’t take into account whether connections are short-lived or long-lived.
Keeping track of connection count may introduce overhead (especially in high-intensive applications).
Least Response Time
Requests are distributed among a pool of servers based on the response time of each server.

Pros:
Optimized response time.
Adaptive to server performance.
Effective use of resources.
Self-healing characteristics.
Cons:
In practice, the response time may be due to waiting I/O operations from the server and not CPU, RAM, or bandwidth consumption. In that case, you may have a few servers doing heavy work while others are just chilling.
Dangerous: the failing servers may start having fewer connections at scale as they will quickly return an error status code. Returning errors usually is much faster than processing a request.
Dependency on monitoring.
Vulnerability to fluctuations. Response times can vary due to network congestion, server load, hardware issues, etc.
Outliers: one bad response time can screw balancing decisions. Taking into account a bigger range of requests adds an overhead.
Risks for hotspots: a subset of servers may receive a disproportionately high volume of traffic due to faster response time.
Potential for Gaming: clients may flood the system to optimize for shorter response time (requesting less data with more requests, prioritizing certain types of traffic).
Weighted Round Robin
Similar to Round Robin, but each server is assigned a weight to indicate its capacity or performance. Servers with higher weights receive more requests.
-
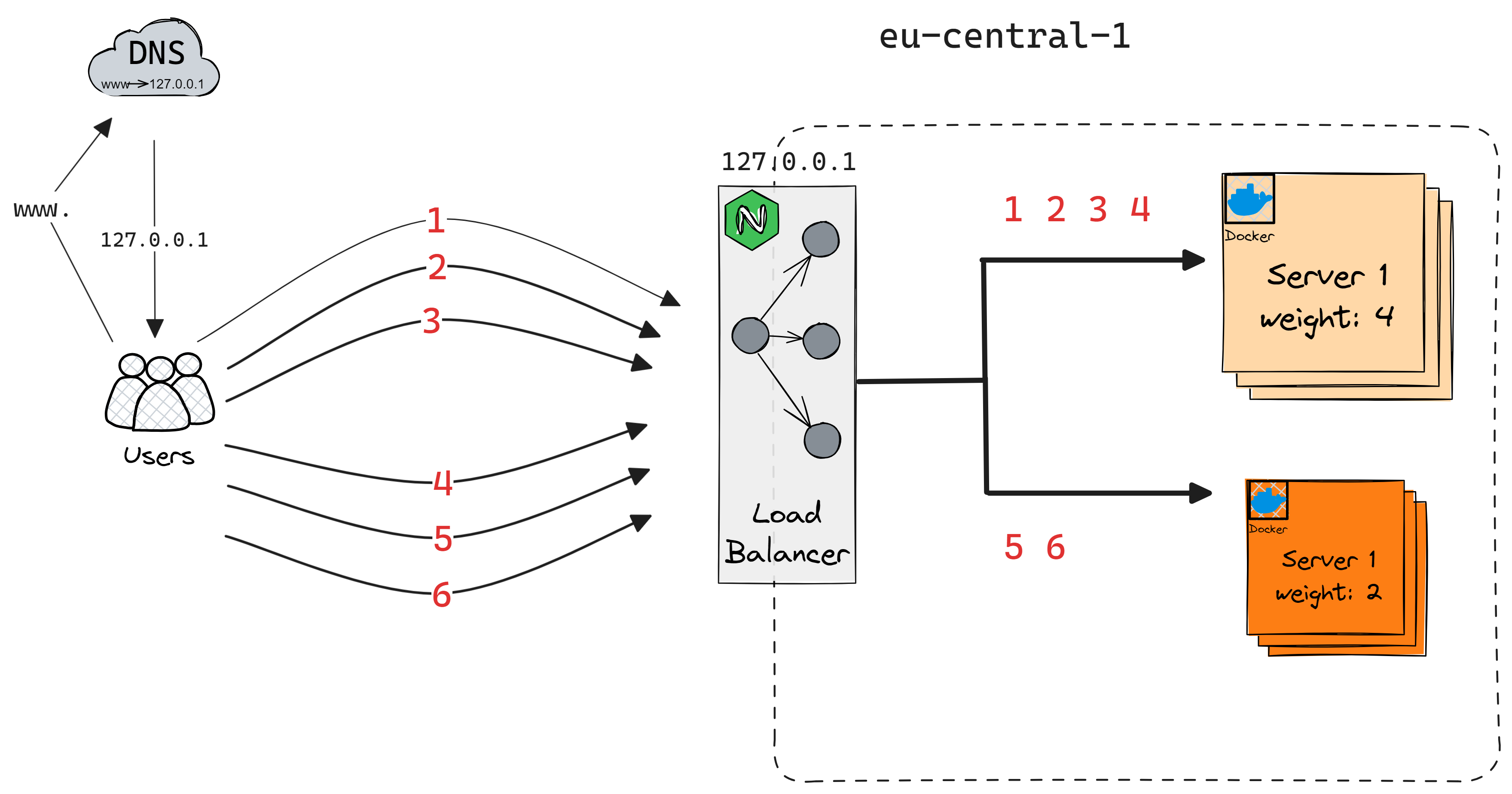
Pros:
Improved load distribution.
Easy to scale.
Fairness adjusted with server capacity.
Cons:
In a dynamic environment, server capacities or load may change frequently.
You should consider the servers' health.
Requests to heavy-weighted servers may start experiencing delays or congestion.
In Google SRE book this approach works better than Simple Round Robin or Least-Loaded Round Robin.
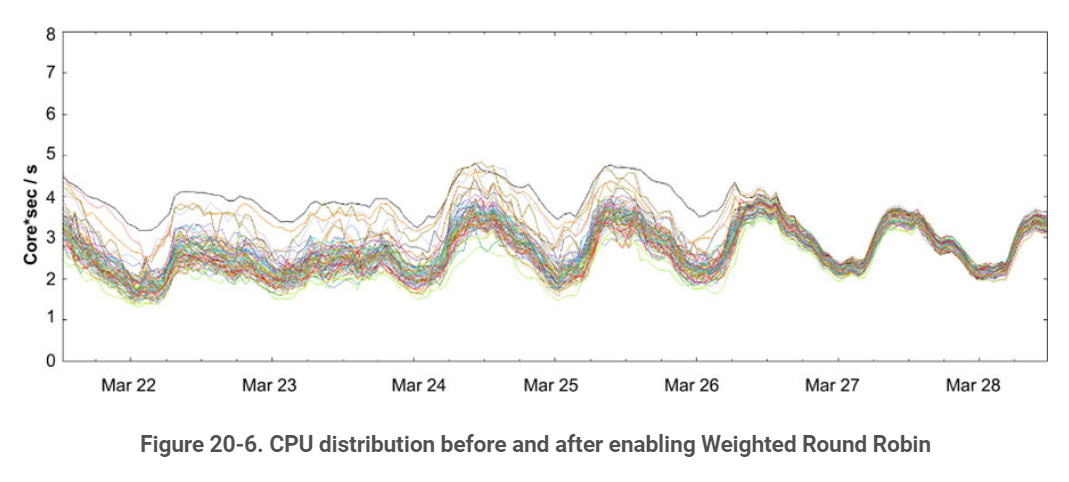
CPU rates after switching from Least-Loaded to Weighted Round Robin. The spread from the least to the most loaded tasks decreased drastically.
Weighted Least Connections
Similar to Least Connection, servers are assigned weights to reflect their capacity or performance.
Cons:
In a dynamic environment server capacities or load may change frequently.
may not be suitable for applications that have long-running connections or require session persistence.
IP/HTTP URL Hashing
Uses a hash function based on the client's IP address or Application layer data to determine which server receives the request. This ensures that requests from the same client are consistently routed to the same server.
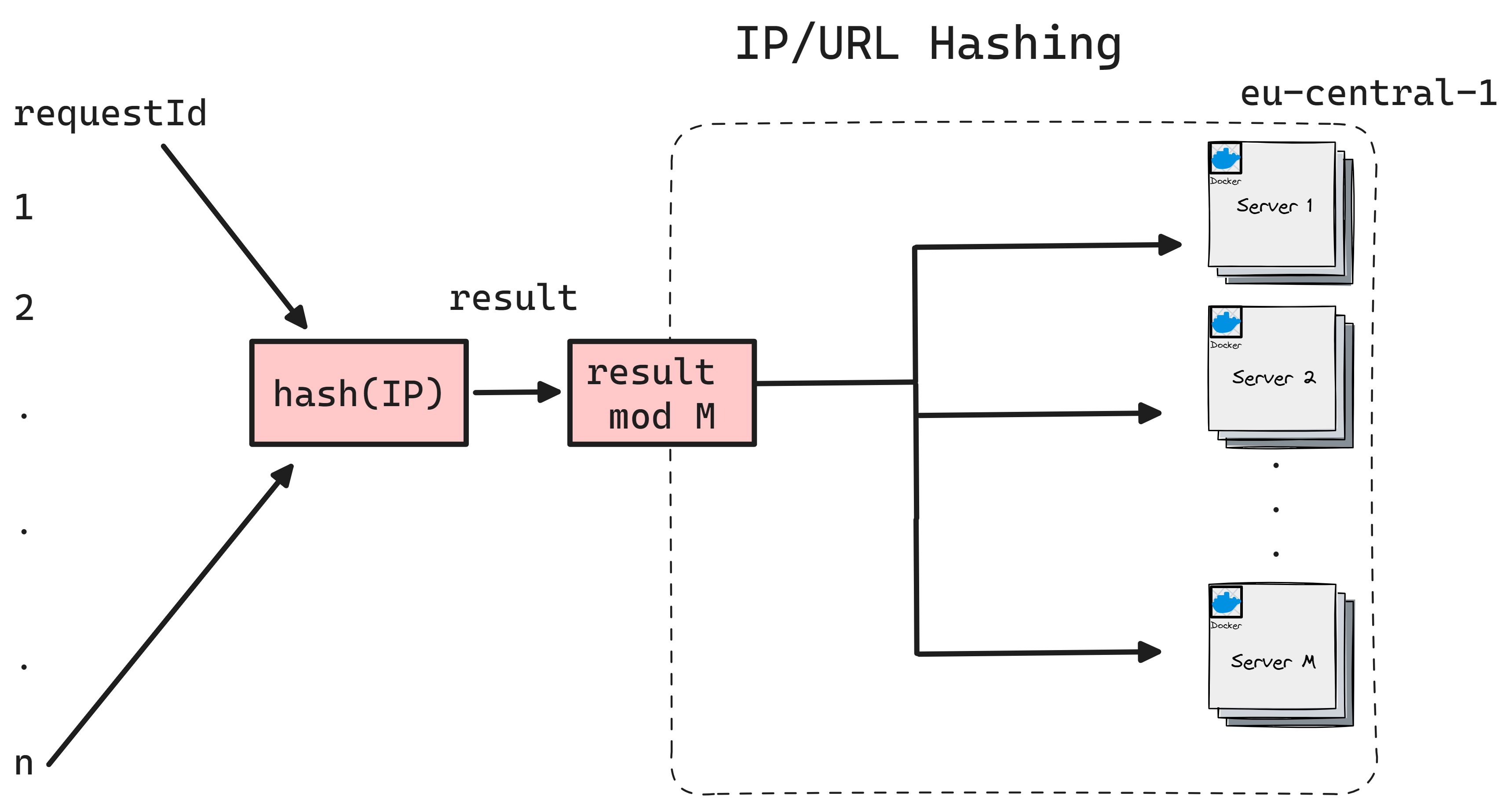
Pros:
Predictable server selection.
Natural session persistence.
Low overhead and simplified configuration.
Good cache utilization.
Cons:
Traffic can be not purely distributed when hash polarization happens (hash imbalance).
No deterministic behavior with dynamic IP allocation.
Doesn’t support multiple sessions for cross-device communication (session inconsistency).
IP hashing depends only on IP. Works purly with NAT gateways.
When a new server is added/removed the mod values change (M+1) or (M-1). This makes all the requests now shifted towards other servers. This is a huge drawback in case you are using local cache on servers.
Power of Two (Choice of Two)
Centralized load balancers do a great work of distributing the load. However, more advanced algorithms bring overhead to the table. A few practical considerations may be additional costs, latency, complexity, and introducing additional points of failure. In large systems with a huge number of requests with similar characteristics, a purely random approach like DNS round robin can work very well.
In The Power of Two Random Choices: A Survey of Techniques and Results, Mitzenmacher shows interesting results about the effect of delayed data on load balancing. Long story short, most requests will be loaded to a previously quiet server for much longer than it takes that server very busy. And because of the distributed nature of systems we deal with the metrics telling load balancers to switch the route will lag. So the very common metrics pattern will occur:
Quiet. Busy. Quiet. Busy. Quiet.
The idea in Mitzenmacker's study shows that by using the Power Of Two mechanism by selecting two random servers and picking the least busy one the overall performance increases significantly and it mitigates the problem.
Join the Shortest Queue (JSQ)
JSQ sends the request to a machine with the lowest number of outstanding requests.
On average it has better performance than Round Robin.
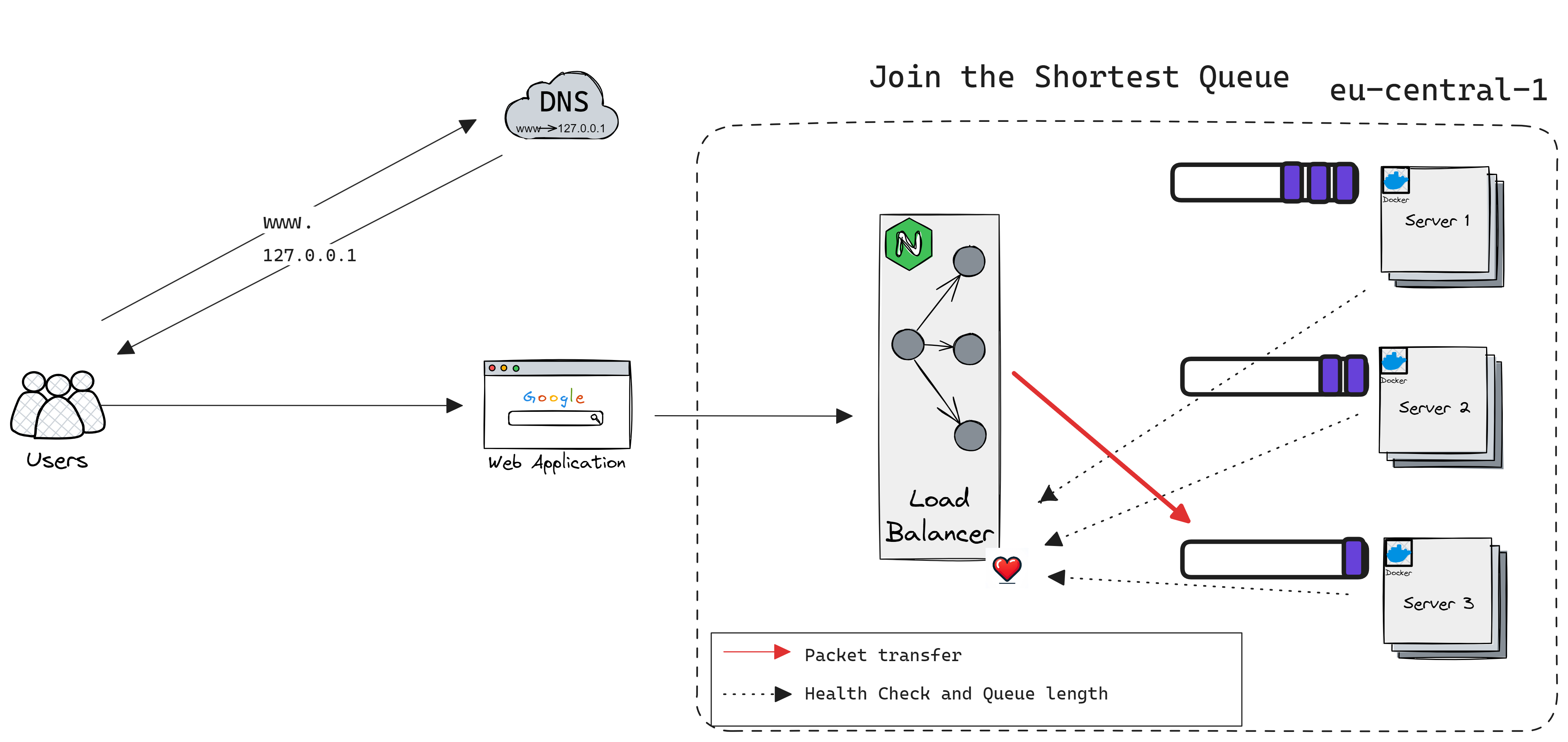
How JSQ Works
Monitoring: Each server in the cluster reports its current queue length, i.e., the number of tasks waiting to be processed, to the load balancer.
Decision Making: Upon the arrival of a new task, the load balancer evaluates the reported queue lengths and selects the server with the shortest queue.
Task Assignment: The task is then assigned to the chosen server for processing.
Limitations of JSQ
- Herding Problem in Clustered Load Balancers:
In a system with multiple load balancers, each making independent decisions based on its local view of server queues, there's a tendency for "herding" behavior. This occurs because all load balancers might simultaneously direct new tasks to the same server perceived as least loaded, quickly overwhelming it. Subsequently, as load balancers shift their focus to the next least utilized server, a cyclical pattern of overloading servers emerges, reducing the overall effectiveness of load balancing.
A solution to this is integrating JSQ with the Choice-of-2 algorithm. Here, instead of choosing the server with the absolute shortest queue, the load balancer randomly picks two servers and then directs the task to the one with the shorter queue among them. This approach significantly mitigates the herding effect by diversifying the servers chosen for new tasks, even if it doesn't completely eliminate the issue due to each load balancer's limited perspective on global server utilization.
- Misleading Short Queues Due to Failing Servers:
Another limitation arises when a server starts failing or processing requests more slowly than usual. The JSQ algorithm might misleadingly identify the server as having a short queue because tasks are processed slowly or not accepted, causing the server to appear less loaded. As a result, more incoming tasks are directed to this failing server, exacerbating the problem by increasing its load without effectively processing it.
This situation requires mechanisms beyond simple load-balancing algorithms, such as health checks and adaptive algorithms that consider server response times and error rates in addition to queue lengths.
Used by Netflix, Spotify, etc.
Consistent Hashing
Let’s say you have a set of four servers {1, 2, 3, 4} and you are using an IP hash algorithm to distribute the load.
Your algorithm will look something like this:
hash(key) mod len
Or more precisely:
hash(request_IP) mod servers_count
What would you do when server 2 dies?
Well, you have a few options:
Accept downtime and wait for another server to jump in and cover the failed server.
You can redirect all requests previously going to server 2 to another server, but now that server will have a 2x load.
You continue as it is and change your servers_count -= 1. However, it leads to massive reshuffling, where a significant portion of requests could hit different servers than before, leading to:
Cache inefficiency: caches that are local to the server will have a cache misses increase significantly, degrading performance.
Overload during reshuffle: the sudden migration of requests can lead to temporary overloads on some servers.
Consistent hashing shines in this scenario: Imagine having 100 keys distributed across 5 servers, with each server handling roughly 20 keys. In the case of normal distribution the bigger the number of keys (requests) the better. If a server is added or removed, the system reshuffles, ensuring each server keeps its original keys while adjusting the load by gaining or losing keys accordingly.
So what is consistent hashing?
Consistent hashing involves a conceptual ring, called a hash ring, which represents a continuous space of hash values. This ring, theoretically having an infinite number of points, allows servers to be placed at various points on it without needing to divide by the number of servers. Both data items (like YouTube video IDs) and servers are hashed using the same hash function and placed on the ring according to their hash values. To determine which server handles a specific data item, you move clockwise around the ring from the data item's hash value until you encounter the first server, which is where the request is directed.


How to implement consistent hashing?
To map requests to servers we use a hash function to determine a request’s position on a conceptual hash ring. We need a system to match each hashed request to a server. This requires:
A list of servers hashes on the ring.
A hash table to associate each request with a server.
One solution is an ordered hash map. To find the server responsible for a request, we:
Use binary search on the server hash list to find the first server hash that is equal to or greater than the request’s hash
Lookup the hash table to find the server linked to this hash.
When adding a new server, it’s placed according to its hash value on the ring. It assumes responsibility for requests in its segment of the ring, up to the next server counter-clockwise.
The ring is not the only way to compute consistent hashing (bounded nodes, hash space partitioning, jump consistent hashing, etc).
Failure? Just take the next server.
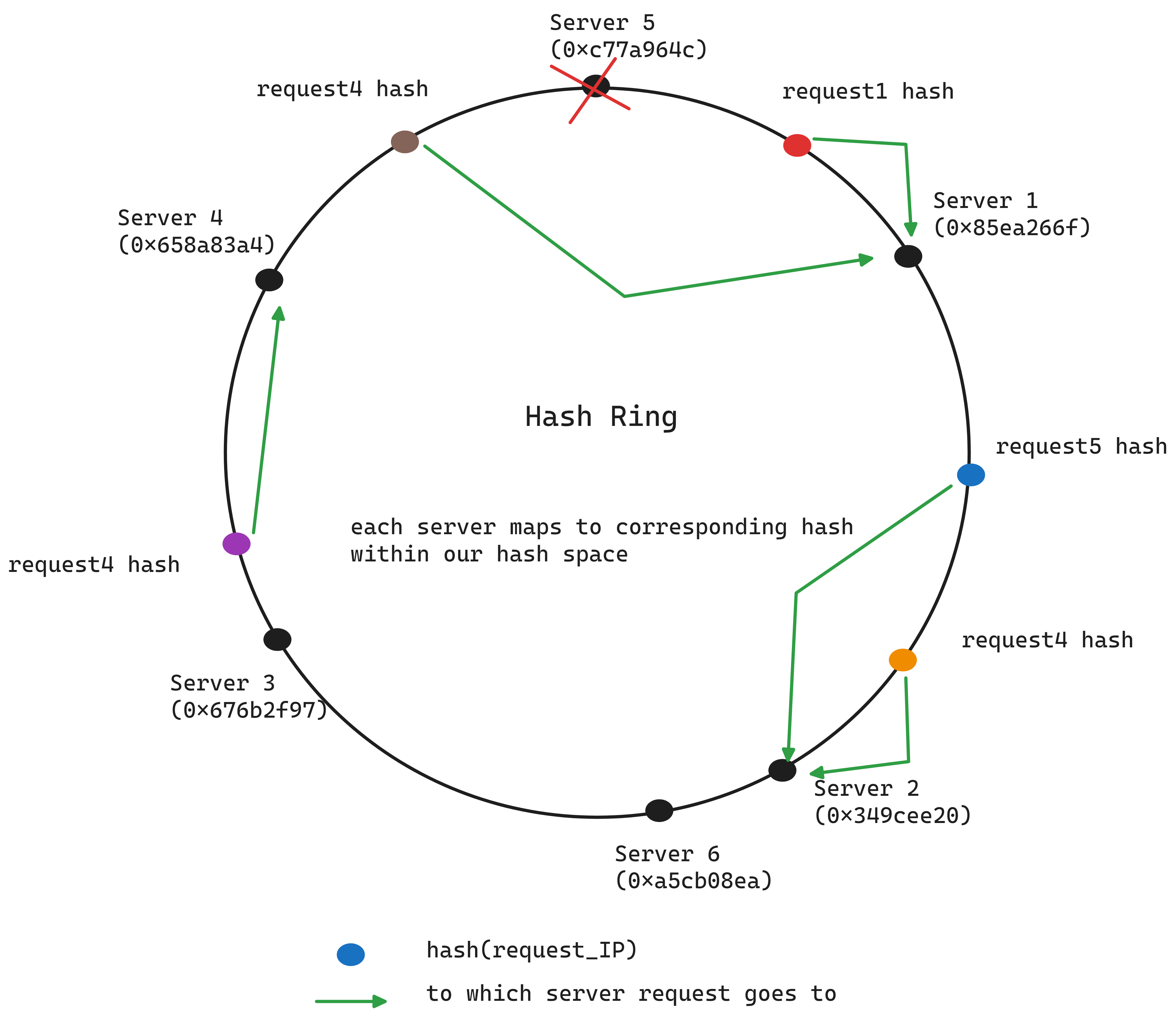
Consistent hashing is widely used in distributed caches (like Memcache), databases (like Cassandra and DynamoDB), and load balancers to efficiently distribute requests to a dynamic set of servers without a significant performance penalty during reshuffling operations.
Pros:
Very useful for servers which have local cache.
In case one of the ring parts becomes extremely hot, you can start splitting your keys or adding more servers pretty simply.
It is used when you need even distribution and redistribution of keys across a large number of servers. And the main part here is re-distribution with minimum reassignment when servers are added/removed.
Servers do not have to talk to each other so no dedicated orchestrator is needed. Load balancers only know the amount of servers available (and potentially their weights).
Cons:
In theory, CH aims to distribute the load evenly, but in practice, the distribution may not be perfectly uniform due to variations in hash functions.
Tuning and optimization challenges: finding the right hash function and adjusting the number of servers to ensure a balanced load can be challenging and often requires trial and error or empirical tuning.
Algorithms Conclusion:
It depends.
A combined approach is widely used (Netflix, Google, etc). For example L4 LB with Consistent Hashing for distributing load between data centers and L7 LB in data centers as a reverse proxy (SSL, rate-limiting, etc) using JSQ + power of two or advanced weighted algorithms. Trial and error is king here.
Try to avoid combined distributed state: prefer local decision-making to avoid complexity and lag of coordination state across a cluster.
Avoid client-side configuration and manual tuning: client-side configurations can lead to synchronization problems and dependencies across different teams, complicating updates and change management.
Scalability
Load Balancer helps in improving throughput by distributing incoming requests across multiple servers, ensuring that no single server becomes overwhelmed:
By evenly distributing traffic, LB prevents any single server from becoming a bottleneck, which is essential during traffic spikes.
Effectively optimizing for resource utilization across the entire pool ensures that processing power, memory, and bandwidth are optimally used.
Also, load balancer can significantly reduce latency by:
Geographical distribution. Placing servers in multiple locations allows load balancers to route requests to the servers closest to the user, minimizing RTT (round trip time).
With session affinity or hashing algorithms, you can ensure that user’s requests are consistently routed to the same server, reducing the latency by avoiding the overhead of establishing new connections and cash misses.
Load balancers can also handle SSL termination, authorization, etc which frees up resources on the web servers and centralized certificate management (at least public certs).
Rate-limiting and DDoS protection can mitigate the risk of influencing the whole system by handing out gates for a small set of tenants/users.
Availability
Up until now, we were discussing load balancer as a single node, which would act as a single point of failure. So if the LB goes down we will have to experience the downtime.
However, practically you have one of the following setups:
Active-active: where two Load Balancers exchange the configuration via network or have a storage for it. Nevertheless, this can introduce additional complexity and a sharing state between LBs.
Active-passive: where you have a primary load balancer handling the requests and occasionally exchange heartbeat with a passive load balancer. When active LB goes down, passive LB picks up the traffic. Commonly it is done in a way where your DNS record points to a virtual IP address and when active LB dies, passive LB takes the virtual IP. The main drawback of this approach is that you may have a potential short downtime during the failover process, as the passive node takes time to become fully operational.
Also, I am not sure, but I suspect that there could be split-brain problems when you have two active LBs serving the same virtual IP address (balancing to databases or working with stateful applications). I don’t have experience and couldn’t find much info on this, however, to mitigate such problems you may read Data-Intensive Application about fencing tokens and other solutions.
- Anycast: A single IP address is assigned to multiple physical servers. Anycast can provide excellent fault tolerance and reduce latency. However, I imagine that similar to active-active setups, anycast requires mechanisms to ensure configuration consistency across LB servers.
Security
Denial of Service Attacks (DDoS)
Syn Flood Attack
A SYN flood is an attack method that exploits part of the normal TCP three-way handshake. The attacker sends a flood of SYN (synchronize) packets to the target’s server, often with a spoofed IP address. The server responds to each packet with a SYN-ACK (acknowledgment) response and waits for a confirming ACK response that never arises. This leads to many open connections hanging and eventually overwhelming the server’s resources.
UDP Flood Attack
A UDP flood, by contrast, involves sending a large number of UDP packets to random (or specific using nmap) ports on remote servers. Since UDP does not require a handshake like TCP, the aim here is to force the application listening at that port to serve the flood data.
DoS and DDoS protection
Chapter 10 of the Google book Build Secure & Reliable Systems: Best Practices for Designing, Implementing and Maintaining Systems is dedicated to mitigating Denial-of-Service Attacks.
While figuring out your best DoS defense strategy you should prioritize strategies that have the greatest impact.
Ideal attack focuses all power on a single resource, e.g:
Bandwidth
Server CPU or memory
Database
Our goal is to protect each of these resources most efficiently.
Defendable architecture: the deeper the attack into the system, the more expensive it is to mitigate. So each layer protects the layer behind it, which is an essential design feature.
Sharable infrastructure (LB in our case) and individual services should be protected individually.
Most services share some common infrastructure, such as network and application LBs.
Layer4 Load Balancer can throttle packet-flooding attacks to protect the application layer load balancers.
Layer7 Load Balancer can throttle application-specific attacks before traffic reaches services.
You should use both L4 and L7 to monitor the incoming traffic and also distribute it to the nearest data center that has available capacity.
You can also do:
Rate-limiting: limiting the number of connections or packets (requests) per second from a single IP or user.
SYN cookie: instead of allocating resources and holding connections open while waiting for ACK, the server sends SYN-ACK with a specific number (cookie) based on the IP and port number of the client. When the client responds with the correct ACK (which is only possible if he receives SYN-ACK and cookies), the server knows its legit request and establishes a connection.
You can use LB metrics to do anomaly detection and behavior analysis.
The overall strategy is:
More cost-effective, since you only do capacity planning on the edge.
Eliminating attack traffic as early as possible saves bandwidth and processing power.
Fun fact or not that fun
Sometimes due to unexpected user behavior, there are other common cases for a sudden increase in traffic. Most of the time, users make independent decisions and their behavior averages out into a smooth demand curve. However, external events can sync their behavior.
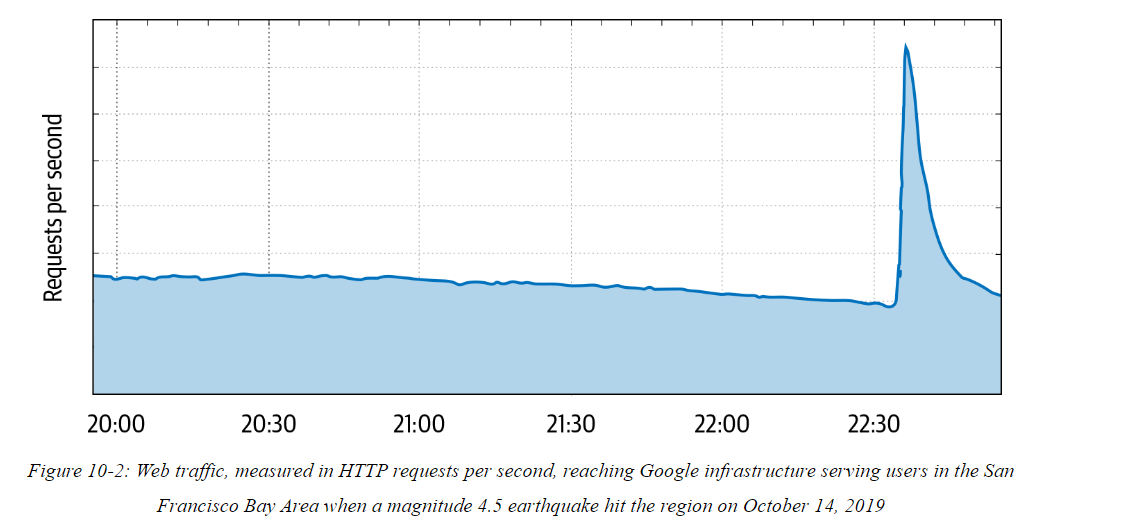
Check the book to learn more 🙂
SSL termination

If you are not familiar with the SSL concept, this great resource explains it in a very simple manner.
As part of the general authentication mechanism the load balancer can be responsible for SSL termination and having the public cert on the edge.
How it works
An SSL cert is installed on the LB. This cert is used to establish a secure connection between the client and LB. When a client initiates a secure connection to the server, it connects to LB. The LB then decrypts the SSL/TLS-encrypted traffic using its SSL certificate.
After decryption, the load balancer can sends the unencrypted traffic to the backend servers. The traffic is sent over a secure network usually inside a datacenter. Most commonly traffic is re-encrypted by the LB before being sent to the backend server, known as SSL re-encryption or SSL bridging. But you are still gaining a lot by being able to put LB closer to the end user than the TCP+SSL 4-way handshake makes RTT lower. And between your LB and backend server, you can have an already established connection.
Then the backend server processes the request and sends the response back to LB, which may encrypt the data again and send it back to the client, completing a secure transaction.
If you manage to read up until here, write a comment so I can A/B test how many of my reads are insane and as a bonus for you:
https://blog.envoyproxy.io/introduction-to-modern-network-load-balancing-and-proxying-a57f6ff80236
https://www.youtube.com/watch?v=PERKHUJYotM&ab_channel=Jordanhasnolife
https://netflixtechblog.com/netflix-edge-load-balancing-695308b5548c
https://sre.google/sre-book/load-balancing-frontend/
https://sre.google/sre-book/load-balancing-datacenter/
https://sre.google/workbook/managing-load/
https://vincent.bernat.ch/en/blog/2018-multi-tier-loadbalancer



